
models.phrases – Phrase (collocation) detection¶
Automatically detect common phrases – aka multi-word expressions, word n-gram collocations – from a stream of sentences.
Inspired by:
Mikolov, et. al: “Distributed Representations of Words and Phrases and their Compositionality”
“Normalized (Pointwise) Mutual Information in Collocation Extraction” by Gerlof Bouma
Examples
>>> from gensim.test.utils import datapath
>>> from gensim.models.word2vec import Text8Corpus
>>> from gensim.models.phrases import Phrases, ENGLISH_CONNECTOR_WORDS
>>>
>>> # Create training corpus. Must be a sequence of sentences (e.g. an iterable or a generator).
>>> sentences = Text8Corpus(datapath('testcorpus.txt'))
>>> # Each sentence must be a list of string tokens:
>>> first_sentence = next(iter(sentences))
>>> print(first_sentence[:10])
['computer', 'human', 'interface', 'computer', 'response', 'survey', 'system', 'time', 'user', 'interface']
>>>
>>> # Train a toy phrase model on our training corpus.
>>> phrase_model = Phrases(sentences, min_count=1, threshold=1, connector_words=ENGLISH_CONNECTOR_WORDS)
>>>
>>> # Apply the trained phrases model to a new, unseen sentence.
>>> new_sentence = ['trees', 'graph', 'minors']
>>> phrase_model[new_sentence]
['trees_graph', 'minors']
>>> # The toy model considered "trees graph" a single phrase => joined the two
>>> # tokens into a single "phrase" token, using our selected `_` delimiter.
>>>
>>> # Apply the trained model to each sentence of a corpus, using the same [] syntax:
>>> for sent in phrase_model[sentences]:
... pass
>>>
>>> # Update the model with two new sentences on the fly.
>>> phrase_model.add_vocab([["hello", "world"], ["meow"]])
>>>
>>> # Export the trained model = use less RAM, faster processing. Model updates no longer possible.
>>> frozen_model = phrase_model.freeze()
>>> # Apply the frozen model; same results as before:
>>> frozen_model[new_sentence]
['trees_graph', 'minors']
>>>
>>> # Save / load models.
>>> frozen_model.save("/tmp/my_phrase_model.pkl")
>>> model_reloaded = Phrases.load("/tmp/my_phrase_model.pkl")
>>> model_reloaded[['trees', 'graph', 'minors']] # apply the reloaded model to a sentence
['trees_graph', 'minors']
- class gensim.models.phrases.FrozenPhrases(phrases_model)¶
Bases:
_PhrasesTransformationMinimal state & functionality exported from a trained
Phrasesmodel.The goal of this class is to cut down memory consumption of Phrases, by discarding model state not strictly needed for the phrase detection task.
Use this instead of Phrases if you do not need to update the bigram statistics with new documents any more.
- Parameters
phrases_model (
Phrases) – Trained phrases instance, to extract all phrases from.
Notes
After the one-time initialization, a
FrozenPhraseswill be much smaller and faster than using the fullPhrasesmodel.Examples
>>> from gensim.test.utils import datapath >>> from gensim.models.word2vec import Text8Corpus >>> from gensim.models.phrases import Phrases, ENGLISH_CONNECTOR_WORDS >>> >>> # Load corpus and train a model. >>> sentences = Text8Corpus(datapath('testcorpus.txt')) >>> phrases = Phrases(sentences, min_count=1, threshold=1, connector_words=ENGLISH_CONNECTOR_WORDS) >>> >>> # Export a FrozenPhrases object that is more efficient but doesn't allow further training. >>> frozen_phrases = phrases.freeze() >>> print(frozen_phrases[sent]) [u'trees_graph', u'minors']
- add_lifecycle_event(event_name, log_level=20, **event)¶
Append an event into the lifecycle_events attribute of this object, and also optionally log the event at log_level.
Events are important moments during the object’s life, such as “model created”, “model saved”, “model loaded”, etc.
The lifecycle_events attribute is persisted across object’s
save()andload()operations. It has no impact on the use of the model, but is useful during debugging and support.Set self.lifecycle_events = None to disable this behaviour. Calls to add_lifecycle_event() will not record events into self.lifecycle_events then.
- Parameters
event_name (str) – Name of the event. Can be any label, e.g. “created”, “stored” etc.
event (dict) –
Key-value mapping to append to self.lifecycle_events. Should be JSON-serializable, so keep it simple. Can be empty.
This method will automatically add the following key-values to event, so you don’t have to specify them:
datetime: the current date & time
gensim: the current Gensim version
python: the current Python version
platform: the current platform
event: the name of this event
log_level (int) – Also log the complete event dict, at the specified log level. Set to False to not log at all.
- analyze_sentence(sentence)¶
Analyze a sentence, concatenating any detected phrases into a single token.
- Parameters
sentence (iterable of str) – Token sequence representing the sentence to be analyzed.
- Yields
(str, {float, None}) – Iterate through the input sentence tokens and yield 2-tuples of: -
(concatenated_phrase_tokens, score)for token sequences that form a phrase. -(word, None)if the token is not a part of a phrase.
- find_phrases(sentences)¶
Get all unique phrases (multi-word expressions) that appear in
sentences, and their scores.- Parameters
sentences (iterable of list of str) – Text corpus.
- Returns
Unique phrases found in
sentences, mapped to their scores.- Return type
dict(str, float)
Example
>>> from gensim.test.utils import datapath >>> from gensim.models.word2vec import Text8Corpus >>> from gensim.models.phrases import Phrases, ENGLISH_CONNECTOR_WORDS >>> >>> sentences = Text8Corpus(datapath('testcorpus.txt')) >>> phrases = Phrases(sentences, min_count=1, threshold=0.1, connector_words=ENGLISH_CONNECTOR_WORDS) >>> >>> for phrase, score in phrases.find_phrases(sentences).items(): ... print(phrase, score)
- classmethod load(*args, **kwargs)¶
Load a previously saved
Phrases/FrozenPhrasesmodel.Handles backwards compatibility from older versions which did not support pluggable scoring functions.
- save(fname_or_handle, separately=None, sep_limit=10485760, ignore=frozenset({}), pickle_protocol=4)¶
Save the object to a file.
- Parameters
fname_or_handle (str or file-like) – Path to output file or already opened file-like object. If the object is a file handle, no special array handling will be performed, all attributes will be saved to the same file.
separately (list of str or None, optional) –
If None, automatically detect large numpy/scipy.sparse arrays in the object being stored, and store them into separate files. This prevent memory errors for large objects, and also allows memory-mapping the large arrays for efficient loading and sharing the large arrays in RAM between multiple processes.
If list of str: store these attributes into separate files. The automated size check is not performed in this case.
sep_limit (int, optional) – Don’t store arrays smaller than this separately. In bytes.
ignore (frozenset of str, optional) – Attributes that shouldn’t be stored at all.
pickle_protocol (int, optional) – Protocol number for pickle.
See also
load()Load object from file.
- score_candidate(word_a, word_b, in_between)¶
Score a single phrase candidate.
- Returns
2-tuple of
(delimiter-joined phrase, phrase score)for a phrase, or(None, None)if not a phrase.- Return type
(str, float)
- gensim.models.phrases.Phraser¶
alias of
FrozenPhrases
- class gensim.models.phrases.Phrases(sentences=None, min_count=5, threshold=10.0, max_vocab_size=40000000, delimiter='_', progress_per=10000, scoring='default', connector_words=frozenset({}))¶
Bases:
_PhrasesTransformationDetect phrases based on collocation counts.
- Parameters
sentences (iterable of list of str, optional) – The sentences iterable can be simply a list, but for larger corpora, consider a generator that streams the sentences directly from disk/network, See
BrownCorpus,Text8CorpusorLineSentencefor such examples.min_count (float, optional) – Ignore all words and bigrams with total collected count lower than this value.
threshold (float, optional) – Represent a score threshold for forming the phrases (higher means fewer phrases). A phrase of words a followed by b is accepted if the score of the phrase is greater than threshold. Heavily depends on concrete scoring-function, see the scoring parameter.
max_vocab_size (int, optional) – Maximum size (number of tokens) of the vocabulary. Used to control pruning of less common words, to keep memory under control. The default of 40M needs about 3.6GB of RAM. Increase/decrease max_vocab_size depending on how much available memory you have.
delimiter (str, optional) – Glue character used to join collocation tokens.
scoring ({'default', 'npmi', function}, optional) –
Specify how potential phrases are scored. scoring can be set with either a string that refers to a built-in scoring function, or with a function with the expected parameter names. Two built-in scoring functions are available by setting scoring to a string:
”default” -
original_scorer().”npmi” -
npmi_scorer().
connector_words (set of str, optional) –
Set of words that may be included within a phrase, without affecting its scoring. No phrase can start nor end with a connector word; a phrase may contain any number of connector words in the middle.
If your texts are in English, set
connector_words=phrases.ENGLISH_CONNECTOR_WORDS.This will cause phrases to include common English articles, prepositions and conjuctions, such as bank_of_america or eye_of_the_beholder.
For other languages or specific applications domains, use custom
connector_wordsthat make sense there:connector_words=frozenset("der die das".split())etc.
Examples
>>> from gensim.test.utils import datapath >>> from gensim.models.word2vec import Text8Corpus >>> from gensim.models.phrases import Phrases, ENGLISH_CONNECTOR_WORDS >>> >>> # Load corpus and train a model. >>> sentences = Text8Corpus(datapath('testcorpus.txt')) >>> phrases = Phrases(sentences, min_count=1, threshold=1, connector_words=ENGLISH_CONNECTOR_WORDS) >>> >>> # Use the model to detect phrases in a new sentence. >>> sent = [u'trees', u'graph', u'minors'] >>> print(phrases[sent]) [u'trees_graph', u'minors'] >>> >>> # Or transform multiple sentences at once. >>> sents = [[u'trees', u'graph', u'minors'], [u'graph', u'minors']] >>> for phrase in phrases[sents]: ... print(phrase) [u'trees_graph', u'minors'] [u'graph_minors'] >>> >>> # Export a FrozenPhrases object that is more efficient but doesn't allow any more training. >>> frozen_phrases = phrases.freeze() >>> print(frozen_phrases[sent]) [u'trees_graph', u'minors']
Notes
The
scoring="npmi"is more robust when dealing with common words that form part of common bigrams, and ranges from -1 to 1, but is slower to calculate than the defaultscoring="default". The default is the PMI-like scoring as described in Mikolov, et. al: “Distributed Representations of Words and Phrases and their Compositionality”.To use your own custom
scoringfunction, pass in a function with the following signature:worda_count- number of corpus occurrences in sentences of the first token in the bigram being scoredwordb_count- number of corpus occurrences in sentences of the second token in the bigram being scoredbigram_count- number of occurrences in sentences of the whole bigramlen_vocab- the number of unique tokens in sentencesmin_count- the min_count setting of the Phrases classcorpus_word_count- the total number of tokens (non-unique) in sentences
The scoring function must accept all these parameters, even if it doesn’t use them in its scoring.
The scoring function must be pickleable.
- add_lifecycle_event(event_name, log_level=20, **event)¶
Append an event into the lifecycle_events attribute of this object, and also optionally log the event at log_level.
Events are important moments during the object’s life, such as “model created”, “model saved”, “model loaded”, etc.
The lifecycle_events attribute is persisted across object’s
save()andload()operations. It has no impact on the use of the model, but is useful during debugging and support.Set self.lifecycle_events = None to disable this behaviour. Calls to add_lifecycle_event() will not record events into self.lifecycle_events then.
- Parameters
event_name (str) – Name of the event. Can be any label, e.g. “created”, “stored” etc.
event (dict) –
Key-value mapping to append to self.lifecycle_events. Should be JSON-serializable, so keep it simple. Can be empty.
This method will automatically add the following key-values to event, so you don’t have to specify them:
datetime: the current date & time
gensim: the current Gensim version
python: the current Python version
platform: the current platform
event: the name of this event
log_level (int) – Also log the complete event dict, at the specified log level. Set to False to not log at all.
- add_vocab(sentences)¶
Update model parameters with new sentences.
- Parameters
sentences (iterable of list of str) – Text corpus to update this model’s parameters from.
Example
>>> from gensim.test.utils import datapath >>> from gensim.models.word2vec import Text8Corpus >>> from gensim.models.phrases import Phrases, ENGLISH_CONNECTOR_WORDS >>> >>> # Train a phrase detector from a text corpus. >>> sentences = Text8Corpus(datapath('testcorpus.txt')) >>> phrases = Phrases(sentences, connector_words=ENGLISH_CONNECTOR_WORDS) # train model >>> assert len(phrases.vocab) == 37 >>> >>> more_sentences = [ ... [u'the', u'mayor', u'of', u'new', u'york', u'was', u'there'], ... [u'machine', u'learning', u'can', u'be', u'new', u'york', u'sometimes'], ... ] >>> >>> phrases.add_vocab(more_sentences) # add new sentences to model >>> assert len(phrases.vocab) == 60
- analyze_sentence(sentence)¶
Analyze a sentence, concatenating any detected phrases into a single token.
- Parameters
sentence (iterable of str) – Token sequence representing the sentence to be analyzed.
- Yields
(str, {float, None}) – Iterate through the input sentence tokens and yield 2-tuples of: -
(concatenated_phrase_tokens, score)for token sequences that form a phrase. -(word, None)if the token is not a part of a phrase.
- export_phrases()¶
Extract all found phrases.
- Returns
Mapping between phrases and their scores.
- Return type
dict(str, float)
- find_phrases(sentences)¶
Get all unique phrases (multi-word expressions) that appear in
sentences, and their scores.- Parameters
sentences (iterable of list of str) – Text corpus.
- Returns
Unique phrases found in
sentences, mapped to their scores.- Return type
dict(str, float)
Example
>>> from gensim.test.utils import datapath >>> from gensim.models.word2vec import Text8Corpus >>> from gensim.models.phrases import Phrases, ENGLISH_CONNECTOR_WORDS >>> >>> sentences = Text8Corpus(datapath('testcorpus.txt')) >>> phrases = Phrases(sentences, min_count=1, threshold=0.1, connector_words=ENGLISH_CONNECTOR_WORDS) >>> >>> for phrase, score in phrases.find_phrases(sentences).items(): ... print(phrase, score)
- freeze()¶
Return an object that contains the bare minimum of information while still allowing phrase detection. See
FrozenPhrases.Use this “frozen model” to dramatically reduce RAM footprint if you don’t plan to make any further changes to your Phrases model.
- Returns
Exported object that’s smaller, faster, but doesn’t support model updates.
- Return type
- classmethod load(*args, **kwargs)¶
Load a previously saved
Phrases/FrozenPhrasesmodel.Handles backwards compatibility from older versions which did not support pluggable scoring functions.
- save(fname_or_handle, separately=None, sep_limit=10485760, ignore=frozenset({}), pickle_protocol=4)¶
Save the object to a file.
- Parameters
fname_or_handle (str or file-like) – Path to output file or already opened file-like object. If the object is a file handle, no special array handling will be performed, all attributes will be saved to the same file.
separately (list of str or None, optional) –
If None, automatically detect large numpy/scipy.sparse arrays in the object being stored, and store them into separate files. This prevent memory errors for large objects, and also allows memory-mapping the large arrays for efficient loading and sharing the large arrays in RAM between multiple processes.
If list of str: store these attributes into separate files. The automated size check is not performed in this case.
sep_limit (int, optional) – Don’t store arrays smaller than this separately. In bytes.
ignore (frozenset of str, optional) – Attributes that shouldn’t be stored at all.
pickle_protocol (int, optional) – Protocol number for pickle.
See also
load()Load object from file.
- score_candidate(word_a, word_b, in_between)¶
Score a single phrase candidate.
- Returns
2-tuple of
(delimiter-joined phrase, phrase score)for a phrase, or(None, None)if not a phrase.- Return type
(str, float)
- gensim.models.phrases.npmi_scorer(worda_count, wordb_count, bigram_count, len_vocab, min_count, corpus_word_count)¶
Calculation NPMI score based on “Normalized (Pointwise) Mutual Information in Colocation Extraction” by Gerlof Bouma.
- Parameters
worda_count (int) – Number of occurrences for first word.
wordb_count (int) – Number of occurrences for second word.
bigram_count (int) – Number of co-occurrences for phrase “worda_wordb”.
len_vocab (int) – Not used.
min_count (int) – Ignore all bigrams with total collected count lower than this value.
corpus_word_count (int) – Total number of words in the corpus.
- Returns
If bigram_count >= min_count, return the collocation score, in the range -1 to 1. Otherwise return -inf.
- Return type
float
Notes
Formula:
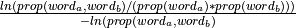 ,
where
,
where 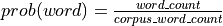
- gensim.models.phrases.original_scorer(worda_count, wordb_count, bigram_count, len_vocab, min_count, corpus_word_count)¶
Bigram scoring function, based on the original Mikolov, et. al: “Distributed Representations of Words and Phrases and their Compositionality”.
- Parameters
worda_count (int) – Number of occurrences for first word.
wordb_count (int) – Number of occurrences for second word.
bigram_count (int) – Number of co-occurrences for phrase “worda_wordb”.
len_vocab (int) – Size of vocabulary.
min_count (int) – Minimum collocation count threshold.
corpus_word_count (int) – Not used in this particular scoring technique.
- Returns
Score for given phrase. Can be negative.
- Return type
float
Notes
Formula:
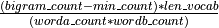 .
.