
models.normmodel – Normalization model¶
- class gensim.models.normmodel.NormModel(corpus=None, norm='l2')¶
Bases:
TransformationABCObjects of this class realize the explicit normalization of vectors (l1 and l2).
Compute the l1 or l2 normalization by normalizing separately for each document in a corpus.
If
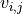 is the ‘i’th component of the vector representing document ‘j’, the l1 normalization is
is the ‘i’th component of the vector representing document ‘j’, the l1 normalization is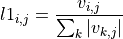
the l2 normalization is
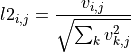
- Parameters
corpus (iterable of iterable of (int, number), optional) – Input corpus.
norm ({'l1', 'l2'}, optional) – Norm used to normalize.
- __getitem__(bow)¶
Call the
normalize().- Parameters
bow (list of (int, number)) – Document in BoW format.
- Returns
Normalized document.
- Return type
list of (int, number)
- add_lifecycle_event(event_name, log_level=20, **event)¶
Append an event into the lifecycle_events attribute of this object, and also optionally log the event at log_level.
Events are important moments during the object’s life, such as “model created”, “model saved”, “model loaded”, etc.
The lifecycle_events attribute is persisted across object’s
save()andload()operations. It has no impact on the use of the model, but is useful during debugging and support.Set self.lifecycle_events = None to disable this behaviour. Calls to add_lifecycle_event() will not record events into self.lifecycle_events then.
- Parameters
event_name (str) – Name of the event. Can be any label, e.g. “created”, “stored” etc.
event (dict) –
Key-value mapping to append to self.lifecycle_events. Should be JSON-serializable, so keep it simple. Can be empty.
This method will automatically add the following key-values to event, so you don’t have to specify them:
datetime: the current date & time
gensim: the current Gensim version
python: the current Python version
platform: the current platform
event: the name of this event
log_level (int) – Also log the complete event dict, at the specified log level. Set to False to not log at all.
- calc_norm(corpus)¶
Calculate the norm by calling
unitvec()with the norm parameter.- Parameters
corpus (iterable of iterable of (int, number)) – Input corpus.
- classmethod load(fname, mmap=None)¶
Load an object previously saved using
save()from a file.- Parameters
fname (str) – Path to file that contains needed object.
mmap (str, optional) – Memory-map option. If the object was saved with large arrays stored separately, you can load these arrays via mmap (shared memory) using mmap=’r’. If the file being loaded is compressed (either ‘.gz’ or ‘.bz2’), then `mmap=None must be set.
See also
save()Save object to file.
- Returns
Object loaded from fname.
- Return type
object
- Raises
AttributeError – When called on an object instance instead of class (this is a class method).
- normalize(bow)¶
Normalize a simple count representation.
- Parameters
bow (list of (int, number)) – Document in BoW format.
- Returns
Normalized document.
- Return type
list of (int, number)
- save(fname_or_handle, separately=None, sep_limit=10485760, ignore=frozenset({}), pickle_protocol=4)¶
Save the object to a file.
- Parameters
fname_or_handle (str or file-like) – Path to output file or already opened file-like object. If the object is a file handle, no special array handling will be performed, all attributes will be saved to the same file.
separately (list of str or None, optional) –
If None, automatically detect large numpy/scipy.sparse arrays in the object being stored, and store them into separate files. This prevent memory errors for large objects, and also allows memory-mapping the large arrays for efficient loading and sharing the large arrays in RAM between multiple processes.
If list of str: store these attributes into separate files. The automated size check is not performed in this case.
sep_limit (int, optional) – Don’t store arrays smaller than this separately. In bytes.
ignore (frozenset of str, optional) – Attributes that shouldn’t be stored at all.
pickle_protocol (int, optional) – Protocol number for pickle.
See also
load()Load object from file.