
Note
Click here to download the full example code
Word2Vec Model¶
Introduces Gensim’s Word2Vec model and demonstrates its use on the Lee Evaluation Corpus.
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
In case you missed the buzz, Word2Vec is a widely used algorithm based on neural networks, commonly referred to as “deep learning” (though word2vec itself is rather shallow). Using large amounts of unannotated plain text, word2vec learns relationships between words automatically. The output are vectors, one vector per word, with remarkable linear relationships that allow us to do things like:
vec(“king”) - vec(“man”) + vec(“woman”) =~ vec(“queen”)
vec(“Montreal Canadiens”) – vec(“Montreal”) + vec(“Toronto”) =~ vec(“Toronto Maple Leafs”).
Word2vec is very useful in automatic text tagging, recommender systems and machine translation.
This tutorial:
Introduces
Word2Vecas an improvement over traditional bag-of-wordsShows off a demo of
Word2Vecusing a pre-trained modelDemonstrates training a new model from your own data
Demonstrates loading and saving models
Introduces several training parameters and demonstrates their effect
Discusses memory requirements
Visualizes Word2Vec embeddings by applying dimensionality reduction
Review: Bag-of-words¶
Note
Feel free to skip these review sections if you’re already familiar with the models.
You may be familiar with the bag-of-words model from the Vector section. This model transforms each document to a fixed-length vector of integers. For example, given the sentences:
John likes to watch movies. Mary likes movies too.John also likes to watch football games. Mary hates football.
The model outputs the vectors:
[1, 2, 1, 1, 2, 1, 1, 0, 0, 0, 0][1, 1, 1, 1, 0, 1, 0, 1, 2, 1, 1]
Each vector has 10 elements, where each element counts the number of times a
particular word occurred in the document.
The order of elements is arbitrary.
In the example above, the order of the elements corresponds to the words:
["John", "likes", "to", "watch", "movies", "Mary", "too", "also", "football", "games", "hates"].
Bag-of-words models are surprisingly effective, but have several weaknesses.
First, they lose all information about word order: “John likes Mary” and “Mary likes John” correspond to identical vectors. There is a solution: bag of n-grams models consider word phrases of length n to represent documents as fixed-length vectors to capture local word order but suffer from data sparsity and high dimensionality.
Second, the model does not attempt to learn the meaning of the underlying
words, and as a consequence, the distance between vectors doesn’t always
reflect the difference in meaning. The Word2Vec model addresses this
second problem.
Introducing: the Word2Vec Model¶
Word2Vec is a more recent model that embeds words in a lower-dimensional
vector space using a shallow neural network. The result is a set of
word-vectors where vectors close together in vector space have similar
meanings based on context, and word-vectors distant to each other have
differing meanings. For example, strong and powerful would be close
together and strong and Paris would be relatively far.
The are two versions of this model and Word2Vec
class implements them both:
Skip-grams (SG)
Continuous-bag-of-words (CBOW)
Important
Don’t let the implementation details below scare you. They’re advanced material: if it’s too much, then move on to the next section.
The Word2Vec Skip-gram model, for example, takes in pairs (word1, word2) generated by moving a window across text data, and trains a 1-hidden-layer neural network based on the synthetic task of given an input word, giving us a predicted probability distribution of nearby words to the input. A virtual one-hot encoding of words goes through a ‘projection layer’ to the hidden layer; these projection weights are later interpreted as the word embeddings. So if the hidden layer has 300 neurons, this network will give us 300-dimensional word embeddings.
Continuous-bag-of-words Word2vec is very similar to the skip-gram model. It is also a 1-hidden-layer neural network. The synthetic training task now uses the average of multiple input context words, rather than a single word as in skip-gram, to predict the center word. Again, the projection weights that turn one-hot words into averageable vectors, of the same width as the hidden layer, are interpreted as the word embeddings.
Word2Vec Demo¶
To see what Word2Vec can do, let’s download a pre-trained model and play
around with it. We will fetch the Word2Vec model trained on part of the
Google News dataset, covering approximately 3 million words and phrases. Such
a model can take hours to train, but since it’s already available,
downloading and loading it with Gensim takes minutes.
Important
The model is approximately 2GB, so you’ll need a decent network connection to proceed. Otherwise, skip ahead to the “Training Your Own Model” section below.
You may also check out an online word2vec demo where you can try
this vector algebra for yourself. That demo runs word2vec on the
entire Google News dataset, of about 100 billion words.
import gensim.downloader as api
wv = api.load('word2vec-google-news-300')
A common operation is to retrieve the vocabulary of a model. That is trivial:
for index, word in enumerate(wv.index_to_key):
if index == 10:
break
print(f"word #{index}/{len(wv.index_to_key)} is {word}")
Out:
word #0/3000000 is </s>
word #1/3000000 is in
word #2/3000000 is for
word #3/3000000 is that
word #4/3000000 is is
word #5/3000000 is on
word #6/3000000 is ##
word #7/3000000 is The
word #8/3000000 is with
word #9/3000000 is said
We can easily obtain vectors for terms the model is familiar with:
vec_king = wv['king']
Unfortunately, the model is unable to infer vectors for unfamiliar words. This is one limitation of Word2Vec: if this limitation matters to you, check out the FastText model.
try:
vec_cameroon = wv['cameroon']
except KeyError:
print("The word 'cameroon' does not appear in this model")
Out:
The word 'cameroon' does not appear in this model
Moving on, Word2Vec supports several word similarity tasks out of the
box. You can see how the similarity intuitively decreases as the words get
less and less similar.
pairs = [
('car', 'minivan'), # a minivan is a kind of car
('car', 'bicycle'), # still a wheeled vehicle
('car', 'airplane'), # ok, no wheels, but still a vehicle
('car', 'cereal'), # ... and so on
('car', 'communism'),
]
for w1, w2 in pairs:
print('%r\t%r\t%.2f' % (w1, w2, wv.similarity(w1, w2)))
Out:
'car' 'minivan' 0.69
'car' 'bicycle' 0.54
'car' 'airplane' 0.42
'car' 'cereal' 0.14
'car' 'communism' 0.06
Print the 5 most similar words to “car” or “minivan”
print(wv.most_similar(positive=['car', 'minivan'], topn=5))
Out:
[('SUV', 0.8532192707061768), ('vehicle', 0.8175783753395081), ('pickup_truck', 0.7763688564300537), ('Jeep', 0.7567334175109863), ('Ford_Explorer', 0.7565720081329346)]
Which of the below does not belong in the sequence?
print(wv.doesnt_match(['fire', 'water', 'land', 'sea', 'air', 'car']))
Out:
car
Training Your Own Model¶
To start, you’ll need some data for training the model. For the following examples, we’ll use the Lee Evaluation Corpus (which you already have if you’ve installed Gensim).
This corpus is small enough to fit entirely in memory, but we’ll implement a memory-friendly iterator that reads it line-by-line to demonstrate how you would handle a larger corpus.
from gensim.test.utils import datapath
from gensim import utils
class MyCorpus:
"""An iterator that yields sentences (lists of str)."""
def __iter__(self):
corpus_path = datapath('lee_background.cor')
for line in open(corpus_path):
# assume there's one document per line, tokens separated by whitespace
yield utils.simple_preprocess(line)
If we wanted to do any custom preprocessing, e.g. decode a non-standard
encoding, lowercase, remove numbers, extract named entities… All of this can
be done inside the MyCorpus iterator and word2vec doesn’t need to
know. All that is required is that the input yields one sentence (list of
utf8 words) after another.
Let’s go ahead and train a model on our corpus. Don’t worry about the training parameters much for now, we’ll revisit them later.
import gensim.models
sentences = MyCorpus()
model = gensim.models.Word2Vec(sentences=sentences)
Once we have our model, we can use it in the same way as in the demo above.
The main part of the model is model.wv, where “wv” stands for “word vectors”.
vec_king = model.wv['king']
Retrieving the vocabulary works the same way:
for index, word in enumerate(wv.index_to_key):
if index == 10:
break
print(f"word #{index}/{len(wv.index_to_key)} is {word}")
Out:
word #0/3000000 is </s>
word #1/3000000 is in
word #2/3000000 is for
word #3/3000000 is that
word #4/3000000 is is
word #5/3000000 is on
word #6/3000000 is ##
word #7/3000000 is The
word #8/3000000 is with
word #9/3000000 is said
Storing and loading models¶
You’ll notice that training non-trivial models can take time. Once you’ve trained your model and it works as expected, you can save it to disk. That way, you don’t have to spend time training it all over again later.
You can store/load models using the standard gensim methods:
import tempfile
with tempfile.NamedTemporaryFile(prefix='gensim-model-', delete=False) as tmp:
temporary_filepath = tmp.name
model.save(temporary_filepath)
#
# The model is now safely stored in the filepath.
# You can copy it to other machines, share it with others, etc.
#
# To load a saved model:
#
new_model = gensim.models.Word2Vec.load(temporary_filepath)
which uses pickle internally, optionally mmap‘ing the model’s internal
large NumPy matrices into virtual memory directly from disk files, for
inter-process memory sharing.
In addition, you can load models created by the original C tool, both using its text and binary formats:
model = gensim.models.KeyedVectors.load_word2vec_format('/tmp/vectors.txt', binary=False)
# using gzipped/bz2 input works too, no need to unzip
model = gensim.models.KeyedVectors.load_word2vec_format('/tmp/vectors.bin.gz', binary=True)
Training Parameters¶
Word2Vec accepts several parameters that affect both training speed and quality.
min_count¶
min_count is for pruning the internal dictionary. Words that appear only
once or twice in a billion-word corpus are probably uninteresting typos and
garbage. In addition, there’s not enough data to make any meaningful training
on those words, so it’s best to ignore them:
default value of min_count=5
model = gensim.models.Word2Vec(sentences, min_count=10)
vector_size¶
vector_size is the number of dimensions (N) of the N-dimensional space that
gensim Word2Vec maps the words onto.
Bigger size values require more training data, but can lead to better (more accurate) models. Reasonable values are in the tens to hundreds.
# The default value of vector_size is 100.
model = gensim.models.Word2Vec(sentences, vector_size=200)
workers¶
workers , the last of the major parameters (full list here)
is for training parallelization, to speed up training:
# default value of workers=3 (tutorial says 1...)
model = gensim.models.Word2Vec(sentences, workers=4)
The workers parameter only has an effect if you have Cython installed. Without Cython, you’ll only be able to use
one core because of the GIL (and word2vec
training will be miserably slow).
Memory¶
At its core, word2vec model parameters are stored as matrices (NumPy
arrays). Each array is #vocabulary (controlled by the min_count parameter)
times vector size (the vector_size parameter) of floats (single precision aka 4 bytes).
Three such matrices are held in RAM (work is underway to reduce that number
to two, or even one). So if your input contains 100,000 unique words, and you
asked for layer vector_size=200, the model will require approx.
100,000*200*4*3 bytes = ~229MB.
There’s a little extra memory needed for storing the vocabulary tree (100,000 words would take a few megabytes), but unless your words are extremely loooong strings, memory footprint will be dominated by the three matrices above.
Evaluating¶
Word2Vec training is an unsupervised task, there’s no good way to
objectively evaluate the result. Evaluation depends on your end application.
Google has released their testing set of about 20,000 syntactic and semantic test examples, following the “A is to B as C is to D” task. It is provided in the ‘datasets’ folder.
For example a syntactic analogy of comparative type is bad:worse;good:?.
There are total of 9 types of syntactic comparisons in the dataset like
plural nouns and nouns of opposite meaning.
The semantic questions contain five types of semantic analogies, such as
capital cities (Paris:France;Tokyo:?) or family members
(brother:sister;dad:?).
Gensim supports the same evaluation set, in exactly the same format:
model.wv.evaluate_word_analogies(datapath('questions-words.txt'))
Out:
(0.0, [{'section': 'capital-common-countries', 'correct': [], 'incorrect': [('CANBERRA', 'AUSTRALIA', 'KABUL', 'AFGHANISTAN'), ('CANBERRA', 'AUSTRALIA', 'PARIS', 'FRANCE'), ('KABUL', 'AFGHANISTAN', 'PARIS', 'FRANCE'), ('KABUL', 'AFGHANISTAN', 'CANBERRA', 'AUSTRALIA'), ('PARIS', 'FRANCE', 'CANBERRA', 'AUSTRALIA'), ('PARIS', 'FRANCE', 'KABUL', 'AFGHANISTAN')]}, {'section': 'capital-world', 'correct': [], 'incorrect': [('CANBERRA', 'AUSTRALIA', 'KABUL', 'AFGHANISTAN'), ('KABUL', 'AFGHANISTAN', 'PARIS', 'FRANCE')]}, {'section': 'currency', 'correct': [], 'incorrect': []}, {'section': 'city-in-state', 'correct': [], 'incorrect': []}, {'section': 'family', 'correct': [], 'incorrect': [('HE', 'SHE', 'HIS', 'HER'), ('HE', 'SHE', 'MAN', 'WOMAN'), ('HIS', 'HER', 'MAN', 'WOMAN'), ('HIS', 'HER', 'HE', 'SHE'), ('MAN', 'WOMAN', 'HE', 'SHE'), ('MAN', 'WOMAN', 'HIS', 'HER')]}, {'section': 'gram1-adjective-to-adverb', 'correct': [], 'incorrect': []}, {'section': 'gram2-opposite', 'correct': [], 'incorrect': []}, {'section': 'gram3-comparative', 'correct': [], 'incorrect': [('GOOD', 'BETTER', 'GREAT', 'GREATER'), ('GOOD', 'BETTER', 'LONG', 'LONGER'), ('GOOD', 'BETTER', 'LOW', 'LOWER'), ('GOOD', 'BETTER', 'SMALL', 'SMALLER'), ('GREAT', 'GREATER', 'LONG', 'LONGER'), ('GREAT', 'GREATER', 'LOW', 'LOWER'), ('GREAT', 'GREATER', 'SMALL', 'SMALLER'), ('GREAT', 'GREATER', 'GOOD', 'BETTER'), ('LONG', 'LONGER', 'LOW', 'LOWER'), ('LONG', 'LONGER', 'SMALL', 'SMALLER'), ('LONG', 'LONGER', 'GOOD', 'BETTER'), ('LONG', 'LONGER', 'GREAT', 'GREATER'), ('LOW', 'LOWER', 'SMALL', 'SMALLER'), ('LOW', 'LOWER', 'GOOD', 'BETTER'), ('LOW', 'LOWER', 'GREAT', 'GREATER'), ('LOW', 'LOWER', 'LONG', 'LONGER'), ('SMALL', 'SMALLER', 'GOOD', 'BETTER'), ('SMALL', 'SMALLER', 'GREAT', 'GREATER'), ('SMALL', 'SMALLER', 'LONG', 'LONGER'), ('SMALL', 'SMALLER', 'LOW', 'LOWER')]}, {'section': 'gram4-superlative', 'correct': [], 'incorrect': [('BIG', 'BIGGEST', 'GOOD', 'BEST'), ('BIG', 'BIGGEST', 'GREAT', 'GREATEST'), ('BIG', 'BIGGEST', 'LARGE', 'LARGEST'), ('GOOD', 'BEST', 'GREAT', 'GREATEST'), ('GOOD', 'BEST', 'LARGE', 'LARGEST'), ('GOOD', 'BEST', 'BIG', 'BIGGEST'), ('GREAT', 'GREATEST', 'LARGE', 'LARGEST'), ('GREAT', 'GREATEST', 'BIG', 'BIGGEST'), ('GREAT', 'GREATEST', 'GOOD', 'BEST'), ('LARGE', 'LARGEST', 'BIG', 'BIGGEST'), ('LARGE', 'LARGEST', 'GOOD', 'BEST'), ('LARGE', 'LARGEST', 'GREAT', 'GREATEST')]}, {'section': 'gram5-present-participle', 'correct': [], 'incorrect': [('GO', 'GOING', 'LOOK', 'LOOKING'), ('GO', 'GOING', 'PLAY', 'PLAYING'), ('GO', 'GOING', 'RUN', 'RUNNING'), ('GO', 'GOING', 'SAY', 'SAYING'), ('LOOK', 'LOOKING', 'PLAY', 'PLAYING'), ('LOOK', 'LOOKING', 'RUN', 'RUNNING'), ('LOOK', 'LOOKING', 'SAY', 'SAYING'), ('LOOK', 'LOOKING', 'GO', 'GOING'), ('PLAY', 'PLAYING', 'RUN', 'RUNNING'), ('PLAY', 'PLAYING', 'SAY', 'SAYING'), ('PLAY', 'PLAYING', 'GO', 'GOING'), ('PLAY', 'PLAYING', 'LOOK', 'LOOKING'), ('RUN', 'RUNNING', 'SAY', 'SAYING'), ('RUN', 'RUNNING', 'GO', 'GOING'), ('RUN', 'RUNNING', 'LOOK', 'LOOKING'), ('RUN', 'RUNNING', 'PLAY', 'PLAYING'), ('SAY', 'SAYING', 'GO', 'GOING'), ('SAY', 'SAYING', 'LOOK', 'LOOKING'), ('SAY', 'SAYING', 'PLAY', 'PLAYING'), ('SAY', 'SAYING', 'RUN', 'RUNNING')]}, {'section': 'gram6-nationality-adjective', 'correct': [], 'incorrect': [('AUSTRALIA', 'AUSTRALIAN', 'FRANCE', 'FRENCH'), ('AUSTRALIA', 'AUSTRALIAN', 'INDIA', 'INDIAN'), ('AUSTRALIA', 'AUSTRALIAN', 'ISRAEL', 'ISRAELI'), ('AUSTRALIA', 'AUSTRALIAN', 'JAPAN', 'JAPANESE'), ('AUSTRALIA', 'AUSTRALIAN', 'SWITZERLAND', 'SWISS'), ('FRANCE', 'FRENCH', 'INDIA', 'INDIAN'), ('FRANCE', 'FRENCH', 'ISRAEL', 'ISRAELI'), ('FRANCE', 'FRENCH', 'JAPAN', 'JAPANESE'), ('FRANCE', 'FRENCH', 'SWITZERLAND', 'SWISS'), ('FRANCE', 'FRENCH', 'AUSTRALIA', 'AUSTRALIAN'), ('INDIA', 'INDIAN', 'ISRAEL', 'ISRAELI'), ('INDIA', 'INDIAN', 'JAPAN', 'JAPANESE'), ('INDIA', 'INDIAN', 'SWITZERLAND', 'SWISS'), ('INDIA', 'INDIAN', 'AUSTRALIA', 'AUSTRALIAN'), ('INDIA', 'INDIAN', 'FRANCE', 'FRENCH'), ('ISRAEL', 'ISRAELI', 'JAPAN', 'JAPANESE'), ('ISRAEL', 'ISRAELI', 'SWITZERLAND', 'SWISS'), ('ISRAEL', 'ISRAELI', 'AUSTRALIA', 'AUSTRALIAN'), ('ISRAEL', 'ISRAELI', 'FRANCE', 'FRENCH'), ('ISRAEL', 'ISRAELI', 'INDIA', 'INDIAN'), ('JAPAN', 'JAPANESE', 'SWITZERLAND', 'SWISS'), ('JAPAN', 'JAPANESE', 'AUSTRALIA', 'AUSTRALIAN'), ('JAPAN', 'JAPANESE', 'FRANCE', 'FRENCH'), ('JAPAN', 'JAPANESE', 'INDIA', 'INDIAN'), ('JAPAN', 'JAPANESE', 'ISRAEL', 'ISRAELI'), ('SWITZERLAND', 'SWISS', 'AUSTRALIA', 'AUSTRALIAN'), ('SWITZERLAND', 'SWISS', 'FRANCE', 'FRENCH'), ('SWITZERLAND', 'SWISS', 'INDIA', 'INDIAN'), ('SWITZERLAND', 'SWISS', 'ISRAEL', 'ISRAELI'), ('SWITZERLAND', 'SWISS', 'JAPAN', 'JAPANESE')]}, {'section': 'gram7-past-tense', 'correct': [], 'incorrect': [('GOING', 'WENT', 'PAYING', 'PAID'), ('GOING', 'WENT', 'PLAYING', 'PLAYED'), ('GOING', 'WENT', 'SAYING', 'SAID'), ('GOING', 'WENT', 'TAKING', 'TOOK'), ('PAYING', 'PAID', 'PLAYING', 'PLAYED'), ('PAYING', 'PAID', 'SAYING', 'SAID'), ('PAYING', 'PAID', 'TAKING', 'TOOK'), ('PAYING', 'PAID', 'GOING', 'WENT'), ('PLAYING', 'PLAYED', 'SAYING', 'SAID'), ('PLAYING', 'PLAYED', 'TAKING', 'TOOK'), ('PLAYING', 'PLAYED', 'GOING', 'WENT'), ('PLAYING', 'PLAYED', 'PAYING', 'PAID'), ('SAYING', 'SAID', 'TAKING', 'TOOK'), ('SAYING', 'SAID', 'GOING', 'WENT'), ('SAYING', 'SAID', 'PAYING', 'PAID'), ('SAYING', 'SAID', 'PLAYING', 'PLAYED'), ('TAKING', 'TOOK', 'GOING', 'WENT'), ('TAKING', 'TOOK', 'PAYING', 'PAID'), ('TAKING', 'TOOK', 'PLAYING', 'PLAYED'), ('TAKING', 'TOOK', 'SAYING', 'SAID')]}, {'section': 'gram8-plural', 'correct': [], 'incorrect': [('BUILDING', 'BUILDINGS', 'CAR', 'CARS'), ('BUILDING', 'BUILDINGS', 'CHILD', 'CHILDREN'), ('BUILDING', 'BUILDINGS', 'MAN', 'MEN'), ('BUILDING', 'BUILDINGS', 'ROAD', 'ROADS'), ('BUILDING', 'BUILDINGS', 'WOMAN', 'WOMEN'), ('CAR', 'CARS', 'CHILD', 'CHILDREN'), ('CAR', 'CARS', 'MAN', 'MEN'), ('CAR', 'CARS', 'ROAD', 'ROADS'), ('CAR', 'CARS', 'WOMAN', 'WOMEN'), ('CAR', 'CARS', 'BUILDING', 'BUILDINGS'), ('CHILD', 'CHILDREN', 'MAN', 'MEN'), ('CHILD', 'CHILDREN', 'ROAD', 'ROADS'), ('CHILD', 'CHILDREN', 'WOMAN', 'WOMEN'), ('CHILD', 'CHILDREN', 'BUILDING', 'BUILDINGS'), ('CHILD', 'CHILDREN', 'CAR', 'CARS'), ('MAN', 'MEN', 'ROAD', 'ROADS'), ('MAN', 'MEN', 'WOMAN', 'WOMEN'), ('MAN', 'MEN', 'BUILDING', 'BUILDINGS'), ('MAN', 'MEN', 'CAR', 'CARS'), ('MAN', 'MEN', 'CHILD', 'CHILDREN'), ('ROAD', 'ROADS', 'WOMAN', 'WOMEN'), ('ROAD', 'ROADS', 'BUILDING', 'BUILDINGS'), ('ROAD', 'ROADS', 'CAR', 'CARS'), ('ROAD', 'ROADS', 'CHILD', 'CHILDREN'), ('ROAD', 'ROADS', 'MAN', 'MEN'), ('WOMAN', 'WOMEN', 'BUILDING', 'BUILDINGS'), ('WOMAN', 'WOMEN', 'CAR', 'CARS'), ('WOMAN', 'WOMEN', 'CHILD', 'CHILDREN'), ('WOMAN', 'WOMEN', 'MAN', 'MEN'), ('WOMAN', 'WOMEN', 'ROAD', 'ROADS')]}, {'section': 'gram9-plural-verbs', 'correct': [], 'incorrect': []}, {'section': 'Total accuracy', 'correct': [], 'incorrect': [('CANBERRA', 'AUSTRALIA', 'KABUL', 'AFGHANISTAN'), ('CANBERRA', 'AUSTRALIA', 'PARIS', 'FRANCE'), ('KABUL', 'AFGHANISTAN', 'PARIS', 'FRANCE'), ('KABUL', 'AFGHANISTAN', 'CANBERRA', 'AUSTRALIA'), ('PARIS', 'FRANCE', 'CANBERRA', 'AUSTRALIA'), ('PARIS', 'FRANCE', 'KABUL', 'AFGHANISTAN'), ('CANBERRA', 'AUSTRALIA', 'KABUL', 'AFGHANISTAN'), ('KABUL', 'AFGHANISTAN', 'PARIS', 'FRANCE'), ('HE', 'SHE', 'HIS', 'HER'), ('HE', 'SHE', 'MAN', 'WOMAN'), ('HIS', 'HER', 'MAN', 'WOMAN'), ('HIS', 'HER', 'HE', 'SHE'), ('MAN', 'WOMAN', 'HE', 'SHE'), ('MAN', 'WOMAN', 'HIS', 'HER'), ('GOOD', 'BETTER', 'GREAT', 'GREATER'), ('GOOD', 'BETTER', 'LONG', 'LONGER'), ('GOOD', 'BETTER', 'LOW', 'LOWER'), ('GOOD', 'BETTER', 'SMALL', 'SMALLER'), ('GREAT', 'GREATER', 'LONG', 'LONGER'), ('GREAT', 'GREATER', 'LOW', 'LOWER'), ('GREAT', 'GREATER', 'SMALL', 'SMALLER'), ('GREAT', 'GREATER', 'GOOD', 'BETTER'), ('LONG', 'LONGER', 'LOW', 'LOWER'), ('LONG', 'LONGER', 'SMALL', 'SMALLER'), ('LONG', 'LONGER', 'GOOD', 'BETTER'), ('LONG', 'LONGER', 'GREAT', 'GREATER'), ('LOW', 'LOWER', 'SMALL', 'SMALLER'), ('LOW', 'LOWER', 'GOOD', 'BETTER'), ('LOW', 'LOWER', 'GREAT', 'GREATER'), ('LOW', 'LOWER', 'LONG', 'LONGER'), ('SMALL', 'SMALLER', 'GOOD', 'BETTER'), ('SMALL', 'SMALLER', 'GREAT', 'GREATER'), ('SMALL', 'SMALLER', 'LONG', 'LONGER'), ('SMALL', 'SMALLER', 'LOW', 'LOWER'), ('BIG', 'BIGGEST', 'GOOD', 'BEST'), ('BIG', 'BIGGEST', 'GREAT', 'GREATEST'), ('BIG', 'BIGGEST', 'LARGE', 'LARGEST'), ('GOOD', 'BEST', 'GREAT', 'GREATEST'), ('GOOD', 'BEST', 'LARGE', 'LARGEST'), ('GOOD', 'BEST', 'BIG', 'BIGGEST'), ('GREAT', 'GREATEST', 'LARGE', 'LARGEST'), ('GREAT', 'GREATEST', 'BIG', 'BIGGEST'), ('GREAT', 'GREATEST', 'GOOD', 'BEST'), ('LARGE', 'LARGEST', 'BIG', 'BIGGEST'), ('LARGE', 'LARGEST', 'GOOD', 'BEST'), ('LARGE', 'LARGEST', 'GREAT', 'GREATEST'), ('GO', 'GOING', 'LOOK', 'LOOKING'), ('GO', 'GOING', 'PLAY', 'PLAYING'), ('GO', 'GOING', 'RUN', 'RUNNING'), ('GO', 'GOING', 'SAY', 'SAYING'), ('LOOK', 'LOOKING', 'PLAY', 'PLAYING'), ('LOOK', 'LOOKING', 'RUN', 'RUNNING'), ('LOOK', 'LOOKING', 'SAY', 'SAYING'), ('LOOK', 'LOOKING', 'GO', 'GOING'), ('PLAY', 'PLAYING', 'RUN', 'RUNNING'), ('PLAY', 'PLAYING', 'SAY', 'SAYING'), ('PLAY', 'PLAYING', 'GO', 'GOING'), ('PLAY', 'PLAYING', 'LOOK', 'LOOKING'), ('RUN', 'RUNNING', 'SAY', 'SAYING'), ('RUN', 'RUNNING', 'GO', 'GOING'), ('RUN', 'RUNNING', 'LOOK', 'LOOKING'), ('RUN', 'RUNNING', 'PLAY', 'PLAYING'), ('SAY', 'SAYING', 'GO', 'GOING'), ('SAY', 'SAYING', 'LOOK', 'LOOKING'), ('SAY', 'SAYING', 'PLAY', 'PLAYING'), ('SAY', 'SAYING', 'RUN', 'RUNNING'), ('AUSTRALIA', 'AUSTRALIAN', 'FRANCE', 'FRENCH'), ('AUSTRALIA', 'AUSTRALIAN', 'INDIA', 'INDIAN'), ('AUSTRALIA', 'AUSTRALIAN', 'ISRAEL', 'ISRAELI'), ('AUSTRALIA', 'AUSTRALIAN', 'JAPAN', 'JAPANESE'), ('AUSTRALIA', 'AUSTRALIAN', 'SWITZERLAND', 'SWISS'), ('FRANCE', 'FRENCH', 'INDIA', 'INDIAN'), ('FRANCE', 'FRENCH', 'ISRAEL', 'ISRAELI'), ('FRANCE', 'FRENCH', 'JAPAN', 'JAPANESE'), ('FRANCE', 'FRENCH', 'SWITZERLAND', 'SWISS'), ('FRANCE', 'FRENCH', 'AUSTRALIA', 'AUSTRALIAN'), ('INDIA', 'INDIAN', 'ISRAEL', 'ISRAELI'), ('INDIA', 'INDIAN', 'JAPAN', 'JAPANESE'), ('INDIA', 'INDIAN', 'SWITZERLAND', 'SWISS'), ('INDIA', 'INDIAN', 'AUSTRALIA', 'AUSTRALIAN'), ('INDIA', 'INDIAN', 'FRANCE', 'FRENCH'), ('ISRAEL', 'ISRAELI', 'JAPAN', 'JAPANESE'), ('ISRAEL', 'ISRAELI', 'SWITZERLAND', 'SWISS'), ('ISRAEL', 'ISRAELI', 'AUSTRALIA', 'AUSTRALIAN'), ('ISRAEL', 'ISRAELI', 'FRANCE', 'FRENCH'), ('ISRAEL', 'ISRAELI', 'INDIA', 'INDIAN'), ('JAPAN', 'JAPANESE', 'SWITZERLAND', 'SWISS'), ('JAPAN', 'JAPANESE', 'AUSTRALIA', 'AUSTRALIAN'), ('JAPAN', 'JAPANESE', 'FRANCE', 'FRENCH'), ('JAPAN', 'JAPANESE', 'INDIA', 'INDIAN'), ('JAPAN', 'JAPANESE', 'ISRAEL', 'ISRAELI'), ('SWITZERLAND', 'SWISS', 'AUSTRALIA', 'AUSTRALIAN'), ('SWITZERLAND', 'SWISS', 'FRANCE', 'FRENCH'), ('SWITZERLAND', 'SWISS', 'INDIA', 'INDIAN'), ('SWITZERLAND', 'SWISS', 'ISRAEL', 'ISRAELI'), ('SWITZERLAND', 'SWISS', 'JAPAN', 'JAPANESE'), ('GOING', 'WENT', 'PAYING', 'PAID'), ('GOING', 'WENT', 'PLAYING', 'PLAYED'), ('GOING', 'WENT', 'SAYING', 'SAID'), ('GOING', 'WENT', 'TAKING', 'TOOK'), ('PAYING', 'PAID', 'PLAYING', 'PLAYED'), ('PAYING', 'PAID', 'SAYING', 'SAID'), ('PAYING', 'PAID', 'TAKING', 'TOOK'), ('PAYING', 'PAID', 'GOING', 'WENT'), ('PLAYING', 'PLAYED', 'SAYING', 'SAID'), ('PLAYING', 'PLAYED', 'TAKING', 'TOOK'), ('PLAYING', 'PLAYED', 'GOING', 'WENT'), ('PLAYING', 'PLAYED', 'PAYING', 'PAID'), ('SAYING', 'SAID', 'TAKING', 'TOOK'), ('SAYING', 'SAID', 'GOING', 'WENT'), ('SAYING', 'SAID', 'PAYING', 'PAID'), ('SAYING', 'SAID', 'PLAYING', 'PLAYED'), ('TAKING', 'TOOK', 'GOING', 'WENT'), ('TAKING', 'TOOK', 'PAYING', 'PAID'), ('TAKING', 'TOOK', 'PLAYING', 'PLAYED'), ('TAKING', 'TOOK', 'SAYING', 'SAID'), ('BUILDING', 'BUILDINGS', 'CAR', 'CARS'), ('BUILDING', 'BUILDINGS', 'CHILD', 'CHILDREN'), ('BUILDING', 'BUILDINGS', 'MAN', 'MEN'), ('BUILDING', 'BUILDINGS', 'ROAD', 'ROADS'), ('BUILDING', 'BUILDINGS', 'WOMAN', 'WOMEN'), ('CAR', 'CARS', 'CHILD', 'CHILDREN'), ('CAR', 'CARS', 'MAN', 'MEN'), ('CAR', 'CARS', 'ROAD', 'ROADS'), ('CAR', 'CARS', 'WOMAN', 'WOMEN'), ('CAR', 'CARS', 'BUILDING', 'BUILDINGS'), ('CHILD', 'CHILDREN', 'MAN', 'MEN'), ('CHILD', 'CHILDREN', 'ROAD', 'ROADS'), ('CHILD', 'CHILDREN', 'WOMAN', 'WOMEN'), ('CHILD', 'CHILDREN', 'BUILDING', 'BUILDINGS'), ('CHILD', 'CHILDREN', 'CAR', 'CARS'), ('MAN', 'MEN', 'ROAD', 'ROADS'), ('MAN', 'MEN', 'WOMAN', 'WOMEN'), ('MAN', 'MEN', 'BUILDING', 'BUILDINGS'), ('MAN', 'MEN', 'CAR', 'CARS'), ('MAN', 'MEN', 'CHILD', 'CHILDREN'), ('ROAD', 'ROADS', 'WOMAN', 'WOMEN'), ('ROAD', 'ROADS', 'BUILDING', 'BUILDINGS'), ('ROAD', 'ROADS', 'CAR', 'CARS'), ('ROAD', 'ROADS', 'CHILD', 'CHILDREN'), ('ROAD', 'ROADS', 'MAN', 'MEN'), ('WOMAN', 'WOMEN', 'BUILDING', 'BUILDINGS'), ('WOMAN', 'WOMEN', 'CAR', 'CARS'), ('WOMAN', 'WOMEN', 'CHILD', 'CHILDREN'), ('WOMAN', 'WOMEN', 'MAN', 'MEN'), ('WOMAN', 'WOMEN', 'ROAD', 'ROADS')]}])
This evaluate_word_analogies method takes an optional parameter
restrict_vocab which limits which test examples are to be considered.
In the December 2016 release of Gensim we added a better way to evaluate semantic similarity.
By default it uses an academic dataset WS-353 but one can create a dataset specific to your business based on it. It contains word pairs together with human-assigned similarity judgments. It measures the relatedness or co-occurrence of two words. For example, ‘coast’ and ‘shore’ are very similar as they appear in the same context. At the same time ‘clothes’ and ‘closet’ are less similar because they are related but not interchangeable.
model.wv.evaluate_word_pairs(datapath('wordsim353.tsv'))
Out:
((0.1014236962315867, 0.44065378924434523), SpearmanrResult(correlation=0.07441989763914543, pvalue=0.5719973648460552), 83.0028328611898)
Important
Good performance on Google’s or WS-353 test set doesn’t mean word2vec will work well in your application, or vice versa. It’s always best to evaluate directly on your intended task. For an example of how to use word2vec in a classifier pipeline, see this tutorial.
Online training / Resuming training¶
Advanced users can load a model and continue training it with more sentences and new vocabulary words:
model = gensim.models.Word2Vec.load(temporary_filepath)
more_sentences = [
['Advanced', 'users', 'can', 'load', 'a', 'model',
'and', 'continue', 'training', 'it', 'with', 'more', 'sentences'],
]
model.build_vocab(more_sentences, update=True)
model.train(more_sentences, total_examples=model.corpus_count, epochs=model.epochs)
# cleaning up temporary file
import os
os.remove(temporary_filepath)
You may need to tweak the total_words parameter to train(),
depending on what learning rate decay you want to simulate.
Note that it’s not possible to resume training with models generated by the C
tool, KeyedVectors.load_word2vec_format(). You can still use them for
querying/similarity, but information vital for training (the vocab tree) is
missing there.
Training Loss Computation¶
The parameter compute_loss can be used to toggle computation of loss
while training the Word2Vec model. The computed loss is stored in the model
attribute running_training_loss and can be retrieved using the function
get_latest_training_loss as follows :
# instantiating and training the Word2Vec model
model_with_loss = gensim.models.Word2Vec(
sentences,
min_count=1,
compute_loss=True,
hs=0,
sg=1,
seed=42,
)
# getting the training loss value
training_loss = model_with_loss.get_latest_training_loss()
print(training_loss)
Out:
1369454.25
Benchmarks¶
Let’s run some benchmarks to see effect of the training loss computation code on training time.
We’ll use the following data for the benchmarks:
Lee Background corpus: included in gensim’s test data
Text8 corpus. To demonstrate the effect of corpus size, we’ll look at the first 1MB, 10MB, 50MB of the corpus, as well as the entire thing.
import io
import os
import gensim.models.word2vec
import gensim.downloader as api
import smart_open
def head(path, size):
with smart_open.open(path) as fin:
return io.StringIO(fin.read(size))
def generate_input_data():
lee_path = datapath('lee_background.cor')
ls = gensim.models.word2vec.LineSentence(lee_path)
ls.name = '25kB'
yield ls
text8_path = api.load('text8').fn
labels = ('1MB', '10MB', '50MB', '100MB')
sizes = (1024 ** 2, 10 * 1024 ** 2, 50 * 1024 ** 2, 100 * 1024 ** 2)
for l, s in zip(labels, sizes):
ls = gensim.models.word2vec.LineSentence(head(text8_path, s))
ls.name = l
yield ls
input_data = list(generate_input_data())
We now compare the training time taken for different combinations of input
data and model training parameters like hs and sg.
For each combination, we repeat the test several times to obtain the mean and standard deviation of the test duration.
# Temporarily reduce logging verbosity
logging.root.level = logging.ERROR
import time
import numpy as np
import pandas as pd
train_time_values = []
seed_val = 42
sg_values = [0, 1]
hs_values = [0, 1]
fast = True
if fast:
input_data_subset = input_data[:3]
else:
input_data_subset = input_data
for data in input_data_subset:
for sg_val in sg_values:
for hs_val in hs_values:
for loss_flag in [True, False]:
time_taken_list = []
for i in range(3):
start_time = time.time()
w2v_model = gensim.models.Word2Vec(
data,
compute_loss=loss_flag,
sg=sg_val,
hs=hs_val,
seed=seed_val,
)
time_taken_list.append(time.time() - start_time)
time_taken_list = np.array(time_taken_list)
time_mean = np.mean(time_taken_list)
time_std = np.std(time_taken_list)
model_result = {
'train_data': data.name,
'compute_loss': loss_flag,
'sg': sg_val,
'hs': hs_val,
'train_time_mean': time_mean,
'train_time_std': time_std,
}
print("Word2vec model #%i: %s" % (len(train_time_values), model_result))
train_time_values.append(model_result)
train_times_table = pd.DataFrame(train_time_values)
train_times_table = train_times_table.sort_values(
by=['train_data', 'sg', 'hs', 'compute_loss'],
ascending=[False, False, True, False],
)
print(train_times_table)
Out:
Word2vec model #0: {'train_data': '25kB', 'compute_loss': True, 'sg': 0, 'hs': 0, 'train_time_mean': 0.25217413902282715, 'train_time_std': 0.020226552024939795}
Word2vec model #1: {'train_data': '25kB', 'compute_loss': False, 'sg': 0, 'hs': 0, 'train_time_mean': 0.25898512204488117, 'train_time_std': 0.026276375796854143}
Word2vec model #2: {'train_data': '25kB', 'compute_loss': True, 'sg': 0, 'hs': 1, 'train_time_mean': 0.4194076855977376, 'train_time_std': 0.0021983060310549808}
Word2vec model #3: {'train_data': '25kB', 'compute_loss': False, 'sg': 0, 'hs': 1, 'train_time_mean': 0.4308760166168213, 'train_time_std': 0.0009999532723555815}
Word2vec model #4: {'train_data': '25kB', 'compute_loss': True, 'sg': 1, 'hs': 0, 'train_time_mean': 0.47211599349975586, 'train_time_std': 0.015136686417800442}
Word2vec model #5: {'train_data': '25kB', 'compute_loss': False, 'sg': 1, 'hs': 0, 'train_time_mean': 0.4695216814676921, 'train_time_std': 0.0033446725418043747}
Word2vec model #6: {'train_data': '25kB', 'compute_loss': True, 'sg': 1, 'hs': 1, 'train_time_mean': 0.9502590497334799, 'train_time_std': 0.005153258425238986}
Word2vec model #7: {'train_data': '25kB', 'compute_loss': False, 'sg': 1, 'hs': 1, 'train_time_mean': 0.9424160321553549, 'train_time_std': 0.009776048211734903}
Word2vec model #8: {'train_data': '1MB', 'compute_loss': True, 'sg': 0, 'hs': 0, 'train_time_mean': 0.6441135406494141, 'train_time_std': 0.00934594899599891}
Word2vec model #9: {'train_data': '1MB', 'compute_loss': False, 'sg': 0, 'hs': 0, 'train_time_mean': 0.656217098236084, 'train_time_std': 0.02703627277086478}
Word2vec model #10: {'train_data': '1MB', 'compute_loss': True, 'sg': 0, 'hs': 1, 'train_time_mean': 1.3150715033213298, 'train_time_std': 0.09457246701267184}
Word2vec model #11: {'train_data': '1MB', 'compute_loss': False, 'sg': 0, 'hs': 1, 'train_time_mean': 1.205832560857137, 'train_time_std': 0.005158620074483131}
Word2vec model #12: {'train_data': '1MB', 'compute_loss': True, 'sg': 1, 'hs': 0, 'train_time_mean': 1.5065066814422607, 'train_time_std': 0.036966116484319765}
Word2vec model #13: {'train_data': '1MB', 'compute_loss': False, 'sg': 1, 'hs': 0, 'train_time_mean': 1.537813663482666, 'train_time_std': 0.01020688183426915}
Word2vec model #14: {'train_data': '1MB', 'compute_loss': True, 'sg': 1, 'hs': 1, 'train_time_mean': 3.302257219950358, 'train_time_std': 0.04523242606424026}
Word2vec model #15: {'train_data': '1MB', 'compute_loss': False, 'sg': 1, 'hs': 1, 'train_time_mean': 3.4928714434305825, 'train_time_std': 0.19327551634697}
Word2vec model #16: {'train_data': '10MB', 'compute_loss': True, 'sg': 0, 'hs': 0, 'train_time_mean': 7.446084260940552, 'train_time_std': 0.7894319693665308}
Word2vec model #17: {'train_data': '10MB', 'compute_loss': False, 'sg': 0, 'hs': 0, 'train_time_mean': 7.060012976328532, 'train_time_std': 0.2136692186366028}
Word2vec model #18: {'train_data': '10MB', 'compute_loss': True, 'sg': 0, 'hs': 1, 'train_time_mean': 14.277136087417603, 'train_time_std': 0.7441633349142932}
Word2vec model #19: {'train_data': '10MB', 'compute_loss': False, 'sg': 0, 'hs': 1, 'train_time_mean': 13.758649031321207, 'train_time_std': 0.37393987718126326}
Word2vec model #20: {'train_data': '10MB', 'compute_loss': True, 'sg': 1, 'hs': 0, 'train_time_mean': 20.35730775197347, 'train_time_std': 0.41241047454786994}
Word2vec model #21: {'train_data': '10MB', 'compute_loss': False, 'sg': 1, 'hs': 0, 'train_time_mean': 21.380844751993816, 'train_time_std': 1.6909472056783184}
Word2vec model #22: {'train_data': '10MB', 'compute_loss': True, 'sg': 1, 'hs': 1, 'train_time_mean': 44.4877184232076, 'train_time_std': 1.1314265197889173}
Word2vec model #23: {'train_data': '10MB', 'compute_loss': False, 'sg': 1, 'hs': 1, 'train_time_mean': 44.517534812291466, 'train_time_std': 1.4472790491207064}
compute_loss hs sg train_data train_time_mean train_time_std
4 True 0 1 25kB 0.472116 0.015137
5 False 0 1 25kB 0.469522 0.003345
6 True 1 1 25kB 0.950259 0.005153
7 False 1 1 25kB 0.942416 0.009776
0 True 0 0 25kB 0.252174 0.020227
1 False 0 0 25kB 0.258985 0.026276
2 True 1 0 25kB 0.419408 0.002198
3 False 1 0 25kB 0.430876 0.001000
12 True 0 1 1MB 1.506507 0.036966
13 False 0 1 1MB 1.537814 0.010207
14 True 1 1 1MB 3.302257 0.045232
15 False 1 1 1MB 3.492871 0.193276
8 True 0 0 1MB 0.644114 0.009346
9 False 0 0 1MB 0.656217 0.027036
10 True 1 0 1MB 1.315072 0.094572
11 False 1 0 1MB 1.205833 0.005159
20 True 0 1 10MB 20.357308 0.412410
21 False 0 1 10MB 21.380845 1.690947
22 True 1 1 10MB 44.487718 1.131427
23 False 1 1 10MB 44.517535 1.447279
16 True 0 0 10MB 7.446084 0.789432
17 False 0 0 10MB 7.060013 0.213669
18 True 1 0 10MB 14.277136 0.744163
19 False 1 0 10MB 13.758649 0.373940
Visualising Word Embeddings¶
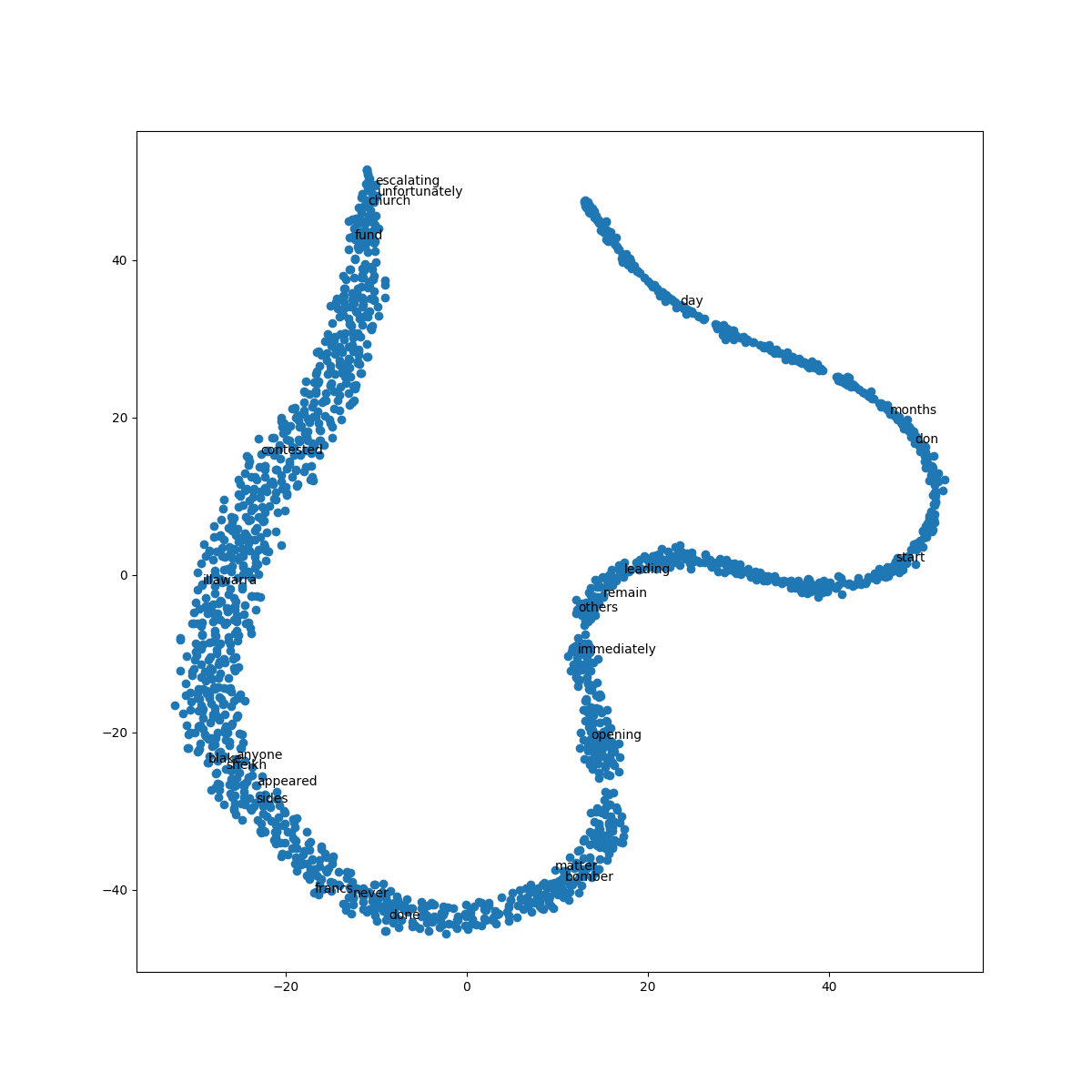
The word embeddings made by the model can be visualised by reducing dimensionality of the words to 2 dimensions using tSNE.
Visualisations can be used to notice semantic and syntactic trends in the data.
Example:
Semantic: words like cat, dog, cow, etc. have a tendency to lie close by
Syntactic: words like run, running or cut, cutting lie close together.
Vector relations like vKing - vMan = vQueen - vWoman can also be noticed.
Important
The model used for the visualisation is trained on a small corpus. Thus some of the relations might not be so clear.
from sklearn.decomposition import IncrementalPCA # inital reduction
from sklearn.manifold import TSNE # final reduction
import numpy as np # array handling
def reduce_dimensions(model):
num_dimensions = 2 # final num dimensions (2D, 3D, etc)
# extract the words & their vectors, as numpy arrays
vectors = np.asarray(model.wv.vectors)
labels = np.asarray(model.wv.index_to_key) # fixed-width numpy strings
# reduce using t-SNE
tsne = TSNE(n_components=num_dimensions, random_state=0)
vectors = tsne.fit_transform(vectors)
x_vals = [v[0] for v in vectors]
y_vals = [v[1] for v in vectors]
return x_vals, y_vals, labels
x_vals, y_vals, labels = reduce_dimensions(model)
def plot_with_plotly(x_vals, y_vals, labels, plot_in_notebook=True):
from plotly.offline import init_notebook_mode, iplot, plot
import plotly.graph_objs as go
trace = go.Scatter(x=x_vals, y=y_vals, mode='text', text=labels)
data = [trace]
if plot_in_notebook:
init_notebook_mode(connected=True)
iplot(data, filename='word-embedding-plot')
else:
plot(data, filename='word-embedding-plot.html')
def plot_with_matplotlib(x_vals, y_vals, labels):
import matplotlib.pyplot as plt
import random
random.seed(0)
plt.figure(figsize=(12, 12))
plt.scatter(x_vals, y_vals)
#
# Label randomly subsampled 25 data points
#
indices = list(range(len(labels)))
selected_indices = random.sample(indices, 25)
for i in selected_indices:
plt.annotate(labels[i], (x_vals[i], y_vals[i]))
try:
get_ipython()
except Exception:
plot_function = plot_with_matplotlib
else:
plot_function = plot_with_plotly
plot_function(x_vals, y_vals, labels)
Conclusion¶
In this tutorial we learned how to train word2vec models on your custom data and also how to evaluate it. Hope that you too will find this popular tool useful in your Machine Learning tasks!
Links¶
Total running time of the script: ( 11 minutes 26.674 seconds)
Estimated memory usage: 7177 MB