
Note
Click here to download the full example code
Fast Similarity Queries with Annoy and Word2Vec¶
Introduces the Annoy library for similarity queries on top of vectors learned by Word2Vec.
LOGS = False # Set to True if you want to see progress in logs.
if LOGS:
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
The Annoy “Approximate Nearest Neighbors Oh Yeah” library enables similarity queries with a Word2Vec model. The current implementation for finding k nearest neighbors in a vector space in Gensim has linear complexity via brute force in the number of indexed documents, although with extremely low constant factors. The retrieved results are exact, which is an overkill in many applications: approximate results retrieved in sub-linear time may be enough. Annoy can find approximate nearest neighbors much faster.
Outline¶
Download Text8 Corpus
Train the Word2Vec model
Construct AnnoyIndex with model & make a similarity query
Compare to the traditional indexer
Persist indices to disk
Save memory by via memory-mapping indices saved to disk
Evaluate relationship of
num_treesto initialization time and accuracyWork with Google’s word2vec C formats
1. Download Text8 corpus¶
import gensim.downloader as api
text8_path = api.load('text8', return_path=True)
print("Using corpus from", text8_path)
Out:
Using corpus from /Users/kofola3/gensim-data/text8/text8.gz
2. Train the Word2Vec model¶
For more details, see Word2Vec Model.
from gensim.models import Word2Vec, KeyedVectors
from gensim.models.word2vec import Text8Corpus
# Using params from Word2Vec_FastText_Comparison
params = {
'alpha': 0.05,
'vector_size': 100,
'window': 5,
'epochs': 5,
'min_count': 5,
'sample': 1e-4,
'sg': 1,
'hs': 0,
'negative': 5,
}
model = Word2Vec(Text8Corpus(text8_path), **params)
wv = model.wv
print("Using trained model", wv)
Out:
Using trained model <gensim.models.keyedvectors.KeyedVectors object at 0x2095fb0f0>
3. Construct AnnoyIndex with model & make a similarity query¶
An instance of AnnoyIndexer needs to be created in order to use Annoy in Gensim.
The AnnoyIndexer class is located in gensim.similarities.annoy.
AnnoyIndexer() takes two parameters:
model: A
Word2VecorDoc2Vecmodel.num_trees: A positive integer.
num_treeseffects the build time and the index size. A larger value will give more accurate results, but larger indexes. More information on what trees in Annoy do can be found here. The relationship betweennum_trees, build time, and accuracy will be investigated later in the tutorial.
Now that we are ready to make a query, lets find the top 5 most similar words
to “science” in the Text8 corpus. To make a similarity query we call
Word2Vec.most_similar like we would traditionally, but with an added
parameter, indexer.
Apart from Annoy, Gensim also supports the NMSLIB indexer. NMSLIB is a similar library to Annoy – both support fast, approximate searches for similar vectors.
from gensim.similarities.annoy import AnnoyIndexer
# 100 trees are being used in this example
annoy_index = AnnoyIndexer(model, 100)
# Derive the vector for the word "science" in our model
vector = wv["science"]
# The instance of AnnoyIndexer we just created is passed
approximate_neighbors = wv.most_similar([vector], topn=11, indexer=annoy_index)
# Neatly print the approximate_neighbors and their corresponding cosine similarity values
print("Approximate Neighbors")
for neighbor in approximate_neighbors:
print(neighbor)
normal_neighbors = wv.most_similar([vector], topn=11)
print("\nExact Neighbors")
for neighbor in normal_neighbors:
print(neighbor)
Out:
Approximate Neighbors
('science', 1.0)
('fiction', 0.6577868759632111)
('crichton', 0.5896251797676086)
('interdisciplinary', 0.5887056291103363)
('astrobiology', 0.5863820314407349)
('multidisciplinary', 0.5813699960708618)
('protoscience', 0.5805026590824127)
('vinge', 0.5781905055046082)
('astronautics', 0.5768974423408508)
('aaas', 0.574912428855896)
('brookings', 0.5739299058914185)
Exact Neighbors
('science', 1.0)
('fiction', 0.7657802700996399)
('crichton', 0.6631850600242615)
('interdisciplinary', 0.661673903465271)
('astrobiology', 0.6578403115272522)
('bimonthly', 0.6501255631446838)
('actuarial', 0.6495736837387085)
('multidisciplinary', 0.6494976878166199)
('protoscience', 0.6480439305305481)
('vinge', 0.6441534757614136)
('xenobiology', 0.6438207030296326)
The closer the cosine similarity of a vector is to 1, the more similar that word is to our query, which was the vector for “science”. There are some differences in the ranking of similar words and the set of words included within the 10 most similar words.
4. Compare to the traditional indexer¶
# Set up the model and vector that we are using in the comparison
annoy_index = AnnoyIndexer(model, 100)
# Dry run to make sure both indexes are fully in RAM
normed_vectors = wv.get_normed_vectors()
vector = normed_vectors[0]
wv.most_similar([vector], topn=5, indexer=annoy_index)
wv.most_similar([vector], topn=5)
import time
import numpy as np
def avg_query_time(annoy_index=None, queries=1000):
"""Average query time of a most_similar method over 1000 random queries."""
total_time = 0
for _ in range(queries):
rand_vec = normed_vectors[np.random.randint(0, len(wv))]
start_time = time.process_time()
wv.most_similar([rand_vec], topn=5, indexer=annoy_index)
total_time += time.process_time() - start_time
return total_time / queries
queries = 1000
gensim_time = avg_query_time(queries=queries)
annoy_time = avg_query_time(annoy_index, queries=queries)
print("Gensim (s/query):\t{0:.5f}".format(gensim_time))
print("Annoy (s/query):\t{0:.5f}".format(annoy_time))
speed_improvement = gensim_time / annoy_time
print ("\nAnnoy is {0:.2f} times faster on average on this particular run".format(speed_improvement))
Out:
Gensim (s/query): 0.00585
Annoy (s/query): 0.00052
Annoy is 11.25 times faster on average on this particular run
This speedup factor is by no means constant and will vary greatly from run to run and is particular to this data set, BLAS setup, Annoy parameters(as tree size increases speedup factor decreases), machine specifications, among other factors.
Important
Initialization time for the annoy indexer was not included in the times. The optimal knn algorithm for you to use will depend on how many queries you need to make and the size of the corpus. If you are making very few similarity queries, the time taken to initialize the annoy indexer will be longer than the time it would take the brute force method to retrieve results. If you are making many queries however, the time it takes to initialize the annoy indexer will be made up for by the incredibly fast retrieval times for queries once the indexer has been initialized
Important
Gensim’s ‘most_similar’ method is using numpy operations in the form of dot product whereas Annoy’s method isnt. If ‘numpy’ on your machine is using one of the BLAS libraries like ATLAS or LAPACK, it’ll run on multiple cores (only if your machine has multicore support ). Check SciPy Cookbook for more details.
5. Persisting indices to disk¶
You can save and load your indexes from/to disk to prevent having to construct them each time. This will create two files on disk, fname and fname.d. Both files are needed to correctly restore all attributes. Before loading an index, you will have to create an empty AnnoyIndexer object.
fname = '/tmp/mymodel.index'
# Persist index to disk
annoy_index.save(fname)
# Load index back
import os.path
if os.path.exists(fname):
annoy_index2 = AnnoyIndexer()
annoy_index2.load(fname)
annoy_index2.model = model
# Results should be identical to above
vector = wv["science"]
approximate_neighbors2 = wv.most_similar([vector], topn=11, indexer=annoy_index2)
for neighbor in approximate_neighbors2:
print(neighbor)
assert approximate_neighbors == approximate_neighbors2
Out:
('science', 1.0)
('fiction', 0.6577868759632111)
('crichton', 0.5896251797676086)
('interdisciplinary', 0.5887056291103363)
('astrobiology', 0.5863820314407349)
('multidisciplinary', 0.5813699960708618)
('protoscience', 0.5805026590824127)
('vinge', 0.5781905055046082)
('astronautics', 0.5768974423408508)
('aaas', 0.574912428855896)
('brookings', 0.5739299058914185)
Be sure to use the same model at load that was used originally, otherwise you will get unexpected behaviors.
6. Save memory via memory-mapping indexes saved to disk¶
Annoy library has a useful feature that indices can be memory-mapped from disk. It saves memory when the same index is used by several processes.
Below are two snippets of code. First one has a separate index for each process. The second snipped shares the index between two processes via memory-mapping. The second example uses less total RAM as it is shared.
# Remove verbosity from code below (if logging active)
if LOGS:
logging.disable(logging.CRITICAL)
from multiprocessing import Process
import os
import psutil
Bad example: two processes load the Word2vec model from disk and create their own Annoy index from that model.
model.save('/tmp/mymodel.pkl')
def f(process_id):
print('Process Id: {}'.format(os.getpid()))
process = psutil.Process(os.getpid())
new_model = Word2Vec.load('/tmp/mymodel.pkl')
vector = new_model.wv["science"]
annoy_index = AnnoyIndexer(new_model, 100)
approximate_neighbors = new_model.wv.most_similar([vector], topn=5, indexer=annoy_index)
print('\nMemory used by process {}: {}\n---'.format(os.getpid(), process.memory_info()))
# Create and run two parallel processes to share the same index file.
p1 = Process(target=f, args=('1',))
p1.start()
p1.join()
p2 = Process(target=f, args=('2',))
p2.start()
p2.join()
Good example: two processes load both the Word2vec model and index from disk and memory-map the index.
model.save('/tmp/mymodel.pkl')
def f(process_id):
print('Process Id: {}'.format(os.getpid()))
process = psutil.Process(os.getpid())
new_model = Word2Vec.load('/tmp/mymodel.pkl')
vector = new_model.wv["science"]
annoy_index = AnnoyIndexer()
annoy_index.load('/tmp/mymodel.index')
annoy_index.model = new_model
approximate_neighbors = new_model.wv.most_similar([vector], topn=5, indexer=annoy_index)
print('\nMemory used by process {}: {}\n---'.format(os.getpid(), process.memory_info()))
# Creating and running two parallel process to share the same index file.
p1 = Process(target=f, args=('1',))
p1.start()
p1.join()
p2 = Process(target=f, args=('2',))
p2.start()
p2.join()
7. Evaluate relationship of num_trees to initialization time and accuracy¶
import matplotlib.pyplot as plt
Build dataset of initialization times and accuracy measures:
exact_results = [element[0] for element in wv.most_similar([normed_vectors[0]], topn=100)]
x_values = []
y_values_init = []
y_values_accuracy = []
for x in range(1, 300, 10):
x_values.append(x)
start_time = time.time()
annoy_index = AnnoyIndexer(model, x)
y_values_init.append(time.time() - start_time)
approximate_results = wv.most_similar([normed_vectors[0]], topn=100, indexer=annoy_index)
top_words = [result[0] for result in approximate_results]
y_values_accuracy.append(len(set(top_words).intersection(exact_results)))
Plot results:
plt.figure(1, figsize=(12, 6))
plt.subplot(121)
plt.plot(x_values, y_values_init)
plt.title("num_trees vs initalization time")
plt.ylabel("Initialization time (s)")
plt.xlabel("num_trees")
plt.subplot(122)
plt.plot(x_values, y_values_accuracy)
plt.title("num_trees vs accuracy")
plt.ylabel("%% accuracy")
plt.xlabel("num_trees")
plt.tight_layout()
plt.show()
Out:
/Volumes/work/workspace/vew/gensim3.6/lib/python3.6/site-packages/matplotlib/figure.py:445: UserWarning:
Matplotlib is currently using agg, which is a non-GUI backend, so cannot show the figure.
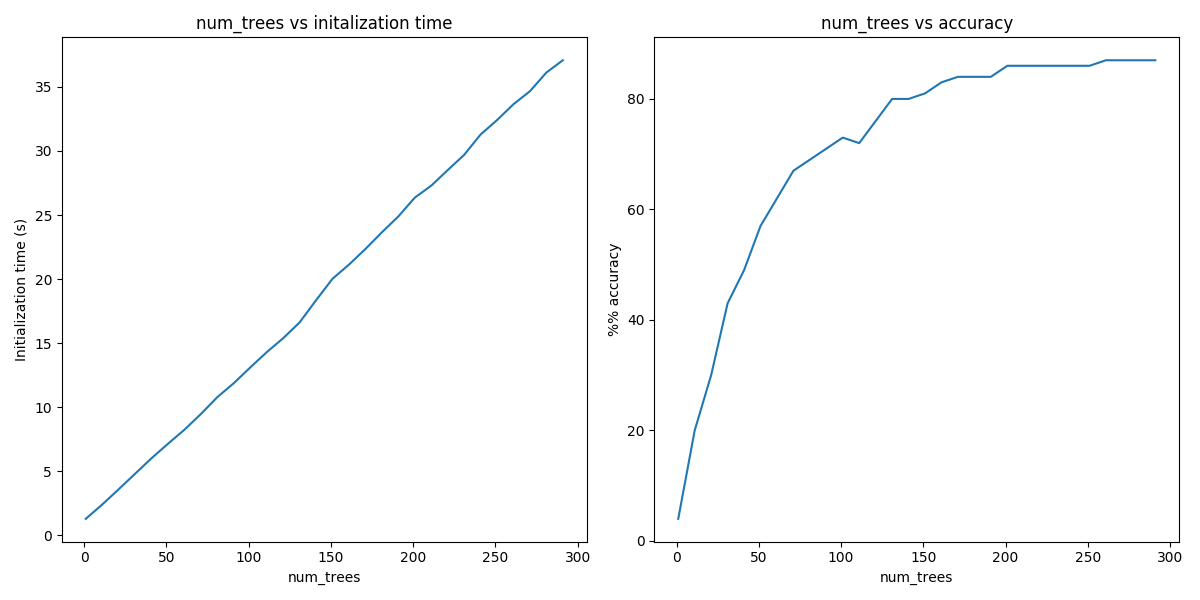
From the above, we can see that the initialization time of the annoy indexer increases in a linear fashion with num_trees. Initialization time will vary from corpus to corpus. In the graph above we used the (tiny) Lee corpus.
Furthermore, in this dataset, the accuracy seems logarithmically related to the number of trees. We see an improvement in accuracy with more trees, but the relationship is nonlinear.
7. Work with Google’s word2vec files¶
Our model can be exported to a word2vec C format. There is a binary and a
plain text word2vec format. Both can be read with a variety of other
software, or imported back into Gensim as a KeyedVectors object.
# To export our model as text
wv.save_word2vec_format('/tmp/vectors.txt', binary=False)
from smart_open import open
# View the first 3 lines of the exported file
# The first line has the total number of entries and the vector dimension count.
# The next lines have a key (a string) followed by its vector.
with open('/tmp/vectors.txt', encoding='utf8') as myfile:
for i in range(3):
print(myfile.readline().strip())
# To import a word2vec text model
wv = KeyedVectors.load_word2vec_format('/tmp/vectors.txt', binary=False)
# To export a model as binary
wv.save_word2vec_format('/tmp/vectors.bin', binary=True)
# To import a word2vec binary model
wv = KeyedVectors.load_word2vec_format('/tmp/vectors.bin', binary=True)
# To create and save Annoy Index from a loaded `KeyedVectors` object (with 100 trees)
annoy_index = AnnoyIndexer(wv, 100)
annoy_index.save('/tmp/mymodel.index')
# Load and test the saved word vectors and saved Annoy index
wv = KeyedVectors.load_word2vec_format('/tmp/vectors.bin', binary=True)
annoy_index = AnnoyIndexer()
annoy_index.load('/tmp/mymodel.index')
annoy_index.model = wv
vector = wv["cat"]
approximate_neighbors = wv.most_similar([vector], topn=11, indexer=annoy_index)
# Neatly print the approximate_neighbors and their corresponding cosine similarity values
print("Approximate Neighbors")
for neighbor in approximate_neighbors:
print(neighbor)
normal_neighbors = wv.most_similar([vector], topn=11)
print("\nExact Neighbors")
for neighbor in normal_neighbors:
print(neighbor)
Out:
71290 100
the 0.1645237 0.049031682 -0.11330697 0.097082675 -0.099474825 -0.08294691 0.007256336 -0.113704175 0.24664731 -0.062123552 -0.024763709 0.25688595 0.059356388 0.28822595 0.18409002 0.17533085 0.12412363 0.05312752 -0.10347493 0.07136696 0.050333817 0.03533254 0.07569087 -0.41796425 -0.13256022 0.30041444 0.26416314 -0.022389138 -0.20686609 -0.21565206 -0.25032488 -0.12548248 0.077188216 0.2432488 -0.1458781 -0.23084323 -0.13360116 -0.01887776 0.21207437 -0.0022163654 0.047225904 0.18978342 0.19625767 -0.02934954 0.005101277 0.11670754 0.11398655 0.33111402 -0.037173223 0.21018152 -0.07217948 -0.0045775156 -0.18228853 -0.065637104 0.16755614 0.20857134 0.1822439 -0.17496146 0.034775164 0.09327986 -0.011131699 -0.009912837 -0.18504283 -0.0043261787 0.03363841 -0.054994233 0.18313456 -0.22603175 0.15427239 0.22330661 0.026417818 0.09543534 0.09841086 -0.41345838 0.14082615 0.13712159 0.070771925 0.06285282 5.9063022e-05 -0.15651035 -0.016906142 0.14885448 0.07121329 -0.23360902 -0.09033932 -0.11270273 -0.0059097605 -0.04875052 -0.04409246 0.103411175 0.00074150774 -0.08402691 -0.07324047 -0.20355953 -0.091564305 -0.11138651 -0.18119322 0.21025972 -0.06939676 0.0016936468
of 0.19971648 0.15359728 -0.1338489 0.12083505 -0.005847811 -0.085402876 -0.075938866 -0.13501053 0.18837708 -0.1259633 0.110350266 0.108376145 0.015276252 0.33608598 0.22733492 0.11238891 -0.053862635 0.073887356 -0.20558539 -0.099394076 -0.0069137346 -0.114128046 0.027444497 -0.35551408 0.007910002 0.23189865 0.2650087 0.03700684 -0.17699398 -0.35950723 -0.32789174 -0.30379272 0.02704152 0.21078588 -0.023837725 -0.21654394 -0.166978 -0.08431874 0.2691367 -0.0023258273 0.06707064 0.09761329 0.24171327 -0.093486875 0.12232643 0.096265465 0.12889618 0.17138048 0.015292533 0.013243989 -0.09338309 0.0905355 -0.26343557 -0.2523928 0.07358186 0.17042407 0.266381 -0.218722 0.059136674 -0.00048657134 -0.0690399 -0.03615013 -0.059233107 -0.066501416 0.04838442 -0.11165278 0.09096755 -0.18076046 0.20482069 0.34460145 0.03740757 0.019260708 0.03930956 -0.37160733 -0.10296658 0.075969525 0.09362528 0.04970148 -0.07688446 -0.12854671 -0.10089095 0.01764436 0.1420408 -0.17590913 -0.20053966 0.14636976 -0.18029185 -0.081263 -0.048385028 0.26456535 -0.055859976 -0.08821882 -0.15724823 -0.17458497 0.010780472 -0.13346615 -0.12641737 0.16775236 -0.20294443 -0.115340725
Approximate Neighbors
('cat', 1.0)
('cats', 0.5968745350837708)
('meow', 0.5941576957702637)
('leopardus', 0.5938971042633057)
('prionailurus', 0.5928952395915985)
('felis', 0.5831491053104401)
('saimiri', 0.5817937552928925)
('rabbits', 0.5794903337955475)
('caracal', 0.5760406851768494)
('sighthound', 0.5754748582839966)
('oncifelis', 0.5718523561954498)
Exact Neighbors
('cat', 1.0000001192092896)
('cats', 0.6749798059463501)
('meow', 0.6705840826034546)
('leopardus', 0.6701608896255493)
('prionailurus', 0.6685314774513245)
('felis', 0.6524706482887268)
('saimiri', 0.6502071619033813)
('rabbits', 0.6463432312011719)
('purr', 0.6449686288833618)
('caracal', 0.640516996383667)
('sighthound', 0.639556884765625)
Recap¶
In this notebook we used the Annoy module to build an indexed approximation of our word embeddings. To do so, we did the following steps:
Download Text8 Corpus
Train Word2Vec Model
Construct AnnoyIndex with model & make a similarity query
Persist indices to disk
Save memory by via memory-mapping indices saved to disk
Evaluate relationship of
num_treesto initialization time and accuracyWork with Google’s word2vec C formats
Total running time of the script: ( 13 minutes 35.756 seconds)
Estimated memory usage: 693 MB