
Note
Click here to download the full example code
Soft Cosine Measure¶
Demonstrates using Gensim’s implemenation of the SCM.
Soft Cosine Measure (SCM) is a promising new tool in machine learning that
allows us to submit a query and return the most relevant documents. This
tutorial introduces SCM and shows how you can compute the SCM similarities
between two documents using the inner_product method.
Soft Cosine Measure basics¶
Soft Cosine Measure (SCM) is a method that allows us to assess the similarity between two documents in a meaningful way, even when they have no words in common. It uses a measure of similarity between words, which can be derived [2] using [word2vec][] [4] vector embeddings of words. It has been shown to outperform many of the state-of-the-art methods in the semantic text similarity task in the context of community question answering [2].
SCM is illustrated below for two very similar sentences. The sentences have no words in common, but by modeling synonymy, SCM is able to accurately measure the similarity between the two sentences. The method also uses the bag-of-words vector representation of the documents (simply put, the word’s frequencies in the documents). The intution behind the method is that we compute standard cosine similarity assuming that the document vectors are expressed in a non-orthogonal basis, where the angle between two basis vectors is derived from the angle between the word2vec embeddings of the corresponding words.
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
img = mpimg.imread('scm-hello.png')
imgplot = plt.imshow(img)
plt.axis('off')
plt.show()
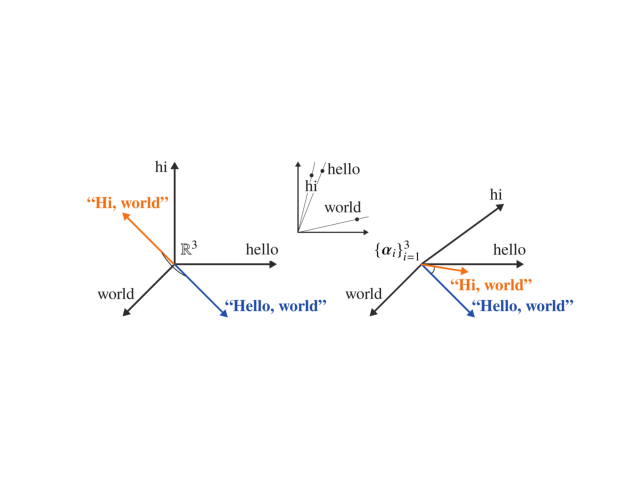
This method was perhaps first introduced in the article “Soft Measure and Soft Cosine Measure: Measure of Features in Vector Space Model” by Grigori Sidorov, Alexander Gelbukh, Helena Gomez-Adorno, and David Pinto.
In this tutorial, we will learn how to use Gensim’s SCM functionality, which
consists of the inner_product method for one-off computation, and the
SoftCosineSimilarity class for corpus-based similarity queries.
Important
If you use Gensim’s SCM functionality, please consider citing [1], [2] and [3].
Computing the Soft Cosine Measure¶
To use SCM, you need some existing word embeddings. You could train your own Word2Vec model, but that is beyond the scope of this tutorial (check out Word2Vec Model if you’re interested). For this tutorial, we’ll be using an existing Word2Vec model.
Let’s take some sentences to compute the distance between.
# Initialize logging.
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
sentence_obama = 'Obama speaks to the media in Illinois'
sentence_president = 'The president greets the press in Chicago'
sentence_orange = 'Oranges are my favorite fruit'
The first two sentences sentences have very similar content, and as such the SCM should be high. By contrast, the third sentence is unrelated to the first two and the SCM should be low.
Before we compute the SCM, we want to remove stopwords (“the”, “to”, etc.), as these do not contribute a lot to the information in the sentences.
# Import and download stopwords from NLTK.
from nltk.corpus import stopwords
from nltk import download
download('stopwords') # Download stopwords list.
stop_words = stopwords.words('english')
def preprocess(sentence):
return [w for w in sentence.lower().split() if w not in stop_words]
sentence_obama = preprocess(sentence_obama)
sentence_president = preprocess(sentence_president)
sentence_orange = preprocess(sentence_orange)
Out:
[nltk_data] Downloading package stopwords to /home/witiko/nltk_data...
[nltk_data] Package stopwords is already up-to-date!
Next, we will build a dictionary and a TF-IDF model, and we will convert the sentences to the bag-of-words format.
from gensim.corpora import Dictionary
documents = [sentence_obama, sentence_president, sentence_orange]
dictionary = Dictionary(documents)
sentence_obama = dictionary.doc2bow(sentence_obama)
sentence_president = dictionary.doc2bow(sentence_president)
sentence_orange = dictionary.doc2bow(sentence_orange)
from gensim.models import TfidfModel
documents = [sentence_obama, sentence_president, sentence_orange]
tfidf = TfidfModel(documents)
sentence_obama = tfidf[sentence_obama]
sentence_president = tfidf[sentence_president]
sentence_orange = tfidf[sentence_orange]
Now, as mentioned earlier, we will be using some downloaded pre-trained embeddings. We load these into a Gensim Word2Vec model class and we build a term similarity mextrix using the embeddings.
Important
The embeddings we have chosen here require a lot of memory.
import gensim.downloader as api
model = api.load('word2vec-google-news-300')
from gensim.similarities import SparseTermSimilarityMatrix, WordEmbeddingSimilarityIndex
termsim_index = WordEmbeddingSimilarityIndex(model)
termsim_matrix = SparseTermSimilarityMatrix(termsim_index, dictionary, tfidf)
So let’s compute SCM using the inner_product method.
similarity = termsim_matrix.inner_product(sentence_obama, sentence_president, normalized=(True, True))
print('similarity = %.4f' % similarity)
Out:
similarity = 0.2575
Let’s try the same thing with two completely unrelated sentences. Notice that the similarity is smaller.
similarity = termsim_matrix.inner_product(sentence_obama, sentence_orange, normalized=(True, True))
print('similarity = %.4f' % similarity)
Out:
similarity = 0.0000
References¶
Grigori Sidorov et al. Soft Similarity and Soft Cosine Measure: Similarity of Features in Vector Space Model, 2014.
Delphine Charlet and Geraldine Damnati, SimBow at SemEval-2017 Task 3: Soft-Cosine Semantic Similarity between Questions for Community Question Answering, 2017.
Vít Novotný. Implementation Notes for the Soft Cosine Measure, 2018.
Tomáš Mikolov et al. Efficient Estimation of Word Representations in Vector Space, 2013.
Total running time of the script: ( 0 minutes 56.707 seconds)
Estimated memory usage: 7701 MB