

topic_coherence.direct_confirmation_measure – Direct confirmation measure module¶This module contains functions to compute direct confirmation on a pair of words or word subsets.
gensim.topic_coherence.direct_confirmation_measure.aggregate_segment_sims(segment_sims, with_std, with_support)¶Compute various statistics from the segment similarities generated via set pairwise comparisons of top-N word lists for a single topic.
segment_sims (iterable of float) – Similarity values to aggregate.
with_std (bool) – Set to True to include standard deviation.
with_support (bool) – Set to True to include number of elements in segment_sims as a statistic in the results returned.
Tuple with (mean[, std[, support]]).
(float[, float[, int]])
Examples
>>> from gensim.topic_coherence import direct_confirmation_measure
>>>
>>> segment_sims = [0.2, 0.5, 1., 0.05]
>>> direct_confirmation_measure.aggregate_segment_sims(segment_sims, True, True)
(0.4375, 0.36293077852394939, 4)
>>> direct_confirmation_measure.aggregate_segment_sims(segment_sims, False, False)
0.4375
gensim.topic_coherence.direct_confirmation_measure.log_conditional_probability(segmented_topics, accumulator, with_std=False, with_support=False)¶Calculate the log-conditional-probability measure which is used by coherence measures such as U_mass.
This is defined as 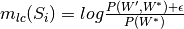 .
.
segmented_topics (list of lists of (int, int)) – Output from the s_one_pre(),
s_one_one().
accumulator (InvertedIndexAccumulator) – Word occurrence accumulator from gensim.topic_coherence.probability_estimation.
with_std (bool, optional) – True to also include standard deviation across topic segment sets in addition to the mean coherence for each topic.
with_support (bool, optional) – True to also include support across topic segments. The support is defined as the number of pairwise similarity comparisons were used to compute the overall topic coherence.
Log conditional probabilities measurement for each topic.
list of float
Examples
>>> from gensim.topic_coherence import direct_confirmation_measure, text_analysis
>>> from collections import namedtuple
>>>
>>> # Create dictionary
>>> id2token = {1: 'test', 2: 'doc'}
>>> token2id = {v: k for k, v in id2token.items()}
>>> dictionary = namedtuple('Dictionary', 'token2id, id2token')(token2id, id2token)
>>>
>>> # Initialize segmented topics and accumulator
>>> segmentation = [[(1, 2)]]
>>>
>>> accumulator = text_analysis.InvertedIndexAccumulator({1, 2}, dictionary)
>>> accumulator._inverted_index = {0: {2, 3, 4}, 1: {3, 5}}
>>> accumulator._num_docs = 5
>>>
>>> # result should be ~ ln(1 / 2) = -0.693147181
>>> result = direct_confirmation_measure.log_conditional_probability(segmentation, accumulator)[0]
gensim.topic_coherence.direct_confirmation_measure.log_ratio_measure(segmented_topics, accumulator, normalize=False, with_std=False, with_support=False)¶Compute log ratio measure for segment_topics.
segmented_topics (list of lists of (int, int)) – Output from the s_one_pre(),
s_one_one().
accumulator (InvertedIndexAccumulator) – Word occurrence accumulator from gensim.topic_coherence.probability_estimation.
normalize (bool, optional) – Details in the “Notes” section.
with_std (bool, optional) – True to also include standard deviation across topic segment sets in addition to the mean coherence for each topic.
with_support (bool, optional) – True to also include support across topic segments. The support is defined as the number of pairwise similarity comparisons were used to compute the overall topic coherence.
Notes
Calculate the log-ratio-measure, popularly known as PMI which is used by coherence measures such as c_v.
This is defined as 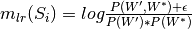
Calculate the normalized-log-ratio-measure, popularly knowns as NPMI
which is used by coherence measures such as c_v.
This is defined as 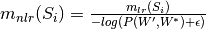
Log ratio measurements for each topic.
list of float
Examples
>>> from gensim.topic_coherence import direct_confirmation_measure, text_analysis
>>> from collections import namedtuple
>>>
>>> # Create dictionary
>>> id2token = {1: 'test', 2: 'doc'}
>>> token2id = {v: k for k, v in id2token.items()}
>>> dictionary = namedtuple('Dictionary', 'token2id, id2token')(token2id, id2token)
>>>
>>> # Initialize segmented topics and accumulator
>>> segmentation = [[(1, 2)]]
>>>
>>> accumulator = text_analysis.InvertedIndexAccumulator({1, 2}, dictionary)
>>> accumulator._inverted_index = {0: {2, 3, 4}, 1: {3, 5}}
>>> accumulator._num_docs = 5
>>>
>>> # result should be ~ ln{(1 / 5) / [(3 / 5) * (2 / 5)]} = -0.182321557
>>> result = direct_confirmation_measure.log_ratio_measure(segmentation, accumulator)[0]
