Practical Data Science in Python¶
This notebook accompanies my talk on "Data Science with Python" at the University of Economics in Prague, December 2014. Questions & comments welcome @RadimRehurek.
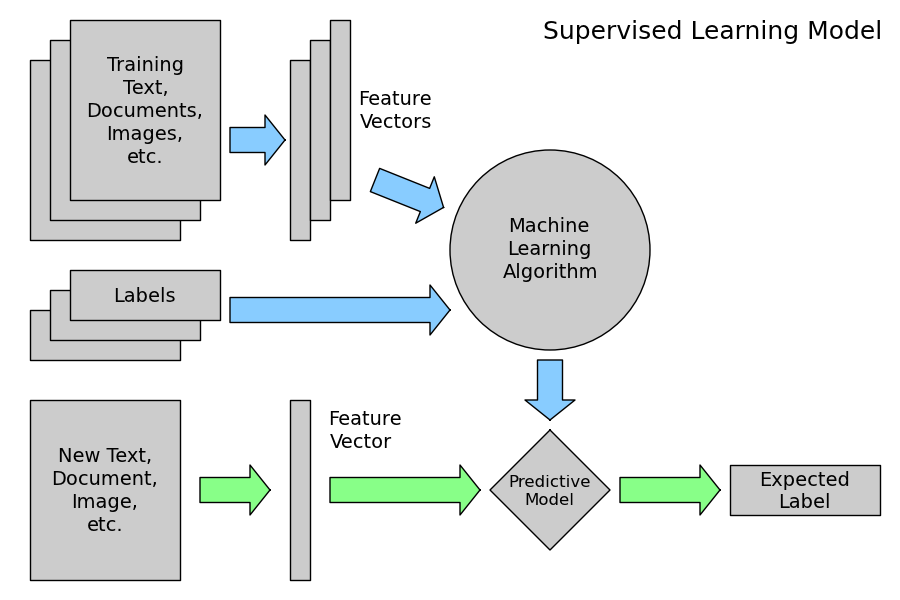
The goal of this talk is to demonstrate some high level, introductory concepts behind (text) machine learning. The concepts are demonstrated by concrete code examples in this notebook, which you can run yourself (after installing IPython, see below), on your own computer.
The talk audience is expected to have some basic programming knowledge (though not necessarily Python) and some basic introductory data mining background. This is not an "advanced talk" for machine learning experts.
The code examples build a working, executable prototype: an app to classify phone SMS messages in English (well, the "SMS kind" of English...) as either "spam" or "ham" (=not spam).

The language used throughout will be Python, a general purpose language helpful in all parts of the pipeline: I/O, data wrangling and preprocessing, model training and evaluation. While Python is by no means the only choice, it offers a unique combination of flexibility, ease of development and performance, thanks to its mature scientific computing ecosystem. Its vast, open source ecosystem also avoids the lock-in (and associated bitrot) of any single specific framework or library.
Python (and of most its libraries) is also platform independent, so you can run this notebook on Windows, Linux or OS X without a change.
One of the Python tools, the IPython notebook = interactive Python rendered as HTML, you're watching right now. We'll go over other practical tools, widely used in the data science industry, below.
- Install the (free) Anaconda Python distribution, including Python itself.
- Install the "natural language processing" TextBlob library: instructions here.
-
Download the source for this notebook to your computer: http://radimrehurek.com/data_science_python/data_science_python.ipynb and run it with:
$ ipython notebook data_science_python.ipynb - Watch the IPython tutorial video for notebook navigation basics.
- Run the first code cell below; if it executes without errors, you're good to go!
End-to-end example: automated spam filtering¶
%matplotlib inline
import matplotlib.pyplot as plt
import csv
from textblob import TextBlob
import pandas
import sklearn
import cPickle
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
from sklearn.naive_bayes import MultinomialNB
from sklearn.svm import SVC, LinearSVC
from sklearn.metrics import classification_report, f1_score, accuracy_score, confusion_matrix
from sklearn.pipeline import Pipeline
from sklearn.grid_search import GridSearchCV
from sklearn.cross_validation import StratifiedKFold, cross_val_score, train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.learning_curve import learning_curve
Step 1: Load data, look around¶
Skipping the real first step (fleshing out specs, finding out what is it we want to be doing -- often highly non-trivial in practice!), let's download the dataset we'll be using in this demo. Go to https://archive.ics.uci.edu/ml/datasets/SMS+Spam+Collection and download the zip file. Unzip it under data subdirectory. You should see a file called SMSSpamCollection, about 0.5MB in size:
$ ls -l data
total 1352
-rw-r--r--@ 1 kofola staff 477907 Mar 15 2011 SMSSpamCollection
-rw-r--r--@ 1 kofola staff 5868 Apr 18 2011 readme
-rw-r-----@ 1 kofola staff 203415 Dec 1 15:30 smsspamcollection.zipThis file contains a collection of more than 5 thousand SMS phone messages (see the readme file for more info):
messages = [line.rstrip() for line in open('./data/SMSSpamCollection')]
print len(messages)
A collection of texts is also sometimes called "corpus". Let's print the first ten messages in this SMS corpus:
for message_no, message in enumerate(messages[:10]):
print message_no, message
We see that this is a TSV ("tab separated values") file, where the first column is a label saying whether the given message is a normal message ("ham") or "spam". The second column is the message itself.
This corpus will be our labeled training set. Using these ham/spam examples, we'll train a machine learning model to learn to discriminate between ham/spam automatically. Then, with a trained model, we'll be able to classify arbitrary unlabeled messages as ham or spam.
Instead of parsing TSV (or CSV, or Excel...) files by hand, we can use Python's pandas library to do the work for us:
messages = pandas.read_csv('./data/SMSSpamCollection', sep='\t', quoting=csv.QUOTE_NONE,
names=["label", "message"])
print messages
With pandas, we can also view aggregate statistics easily:
messages.groupby('label').describe()
How long are the messages?
messages['length'] = messages['message'].map(lambda text: len(text))
print messages.head()
messages.length.plot(bins=20, kind='hist')

messages.length.describe()
What is that super long message?
print list(messages.message[messages.length > 900])
Is there any difference in message length between spam and ham?
messages.hist(column='length', by='label', bins=50)

Good fun, but how do we make computer understand the plain text messages themselves? Or can it under such malformed gibberish at all?
Step 2: Data preprocessing¶
In this section we'll massage the raw messages (sequence of characters) into vectors (sequences of numbers).
The mapping is not 1-to-1; we'll use the bag-of-words approach, where each unique word in a text will be represented by one number.
As a first step, let's write a function that will split a message into its individual words:
def split_into_tokens(message):
message = unicode(message, 'utf8') # convert bytes into proper unicode
return TextBlob(message).words
Here are some of the original texts again:
messages.message.head()
...and here are the same messages, tokenized:
messages.message.head().apply(split_into_tokens)
NLP questions:
- Do capital letters carry information?
- Does distinguishing inflected form ("goes" vs. "go") carry information?
- Do interjections, determiners carry information?
In other words, we want to better "normalize" the text.
With textblob, we'd detect part-of-speech (POS) tags with:
TextBlob("Hello world, how is it going?").tags # list of (word, POS) pairs
and normalize words into their base form (lemmas) with:
def split_into_lemmas(message):
message = unicode(message, 'utf8').lower()
words = TextBlob(message).words
# for each word, take its "base form" = lemma
return [word.lemma for word in words]
messages.message.head().apply(split_into_lemmas)
Better. You can probably think of many more ways to improve the preprocessing: decoding HTML entities (those & and < we saw above); filtering out stop words (pronouns etc); adding more features, such as an word-in-all-caps indicator and so on.
Step 3: Data to vectors¶
Now we'll convert each message, represented as a list of tokens (lemmas) above, into a vector that machine learning models can understand.
Doing that requires essentially three steps, in the bag-of-words model:
- counting how many times does a word occur in each message (term frequency)
- weighting the counts, so that frequent tokens get lower weight (inverse document frequency)
- normalizing the vectors to unit length, to abstract from the original text length (L2 norm)
Each vector has as many dimensions as there are unique words in the SMS corpus:
bow_transformer = CountVectorizer(analyzer=split_into_lemmas).fit(messages['message'])
print len(bow_transformer.vocabulary_)
Here we used scikit-learn (sklearn), a powerful Python library for teaching machine learning. It contains a multitude of various methods and options.
Let's take one text message and get its bag-of-words counts as a vector, putting to use our new bow_transformer:
message4 = messages['message'][3]
print message4
bow4 = bow_transformer.transform([message4])
print bow4
print bow4.shape
So, nine unique words in message nr. 4, two of them appear twice, the rest only once. Sanity check: what are these words the appear twice?
print bow_transformer.get_feature_names()[6736]
print bow_transformer.get_feature_names()[8013]
The bag-of-words counts for the entire SMS corpus are a large, sparse matrix:
messages_bow = bow_transformer.transform(messages['message'])
print 'sparse matrix shape:', messages_bow.shape
print 'number of non-zeros:', messages_bow.nnz
print 'sparsity: %.2f%%' % (100.0 * messages_bow.nnz / (messages_bow.shape[0] * messages_bow.shape[1]))
And finally, after the counting, the term weighting and normalization can be done with TF-IDF, using scikit-learn's TfidfTransformer:
tfidf_transformer = TfidfTransformer().fit(messages_bow)
tfidf4 = tfidf_transformer.transform(bow4)
print tfidf4
What is the IDF (inverse document frequency) of the word "u"? Of word "university"?
print tfidf_transformer.idf_[bow_transformer.vocabulary_['u']]
print tfidf_transformer.idf_[bow_transformer.vocabulary_['university']]
To transform the entire bag-of-words corpus into TF-IDF corpus at once:
messages_tfidf = tfidf_transformer.transform(messages_bow)
print messages_tfidf.shape
There are a multitude of ways in which data can be proprocessed and vectorized. These two steps, also called "feature engineering", are typically the most time consuming and "unsexy" parts of building a predictive pipeline, but they are very important and require some experience. The trick is to evaluate constantly: analyze model for the errors it makes, improve data cleaning & preprocessing, brainstorm for new features, evaluate...
Step 4: Training a model, detecting spam¶
With messages represented as vectors, we can finally train our spam/ham classifier. This part is pretty straightforward, and there are many libraries that realize the training algorithms.
We'll be using scikit-learn here, choosing the Naive Bayes classifier to start with:
%time spam_detector = MultinomialNB().fit(messages_tfidf, messages['label'])
Let's try classifying our single random message:
print 'predicted:', spam_detector.predict(tfidf4)[0]
print 'expected:', messages.label[3]
Hooray! You can try it with your own texts, too.
A natural question is to ask, how many messages do we classify correctly overall?
all_predictions = spam_detector.predict(messages_tfidf)
print all_predictions
print 'accuracy', accuracy_score(messages['label'], all_predictions)
print 'confusion matrix\n', confusion_matrix(messages['label'], all_predictions)
print '(row=expected, col=predicted)'
plt.matshow(confusion_matrix(messages['label'], all_predictions), cmap=plt.cm.binary, interpolation='nearest')
plt.title('confusion matrix')
plt.colorbar()
plt.ylabel('expected label')
plt.xlabel('predicted label')

From this confusion matrix, we can compute precision and recall, or their combination (harmonic mean) F1:
print classification_report(messages['label'], all_predictions)
There are quite a few possible metrics for evaluating model performance. Which one is the most suitable depends on the task. For example, the cost of mispredicting "spam" as "ham" is probably much lower than mispredicting "ham" as "spam".
Step 5: How to run experiments?¶
In the above "evaluation", we committed a cardinal sin. For simplicity of demonstration, we evaluated accuracy on the same data we used for training. Never evaluate on the same dataset you train on! Bad! Incest!
Such evaluation tells us nothing about the true predictive power of our model. If we simply remembered each example during training, the accuracy on training data would trivially be 100%, even though we wouldn't be able to classify any new messages.
A proper way is to split the data into a training/test set, where the model only ever sees the training data during its model fitting and parameter tuning. The test data is never used in any way -- thanks to this process, we make sure we are not "cheating", and that our final evaluation on test data is representative of true predictive performance.
msg_train, msg_test, label_train, label_test = \
train_test_split(messages['message'], messages['label'], test_size=0.2)
print len(msg_train), len(msg_test), len(msg_train) + len(msg_test)
So, as requested, the test size is 20% of the entire dataset (1115 messages out of total 5574), and the training is the rest (4459 out of 5574).
Let's recap the entire pipeline up to this point, putting the steps explicitly into scikit-learn's Pipeline:
pipeline = Pipeline([
('bow', CountVectorizer(analyzer=split_into_lemmas)), # strings to token integer counts
('tfidf', TfidfTransformer()), # integer counts to weighted TF-IDF scores
('classifier', MultinomialNB()), # train on TF-IDF vectors w/ Naive Bayes classifier
])
A common practice is to partition the training set again, into smaller subsets; for example, 5 equally sized subsets. Then we train the model on four parts, and compute accuracy on the last part (called "validation set"). Repeated five times (taking different part for evaluation each time), we get a sense of model "stability". If the model gives wildly different scores for different subsets, it's a sign something is wrong (bad data, or bad model variance). Go back, analyze errors, re-check input data for garbage, re-check data cleaning.
In our case, everything goes smoothly though:
scores = cross_val_score(pipeline, # steps to convert raw messages into models
msg_train, # training data
label_train, # training labels
cv=10, # split data randomly into 10 parts: 9 for training, 1 for scoring
scoring='accuracy', # which scoring metric?
n_jobs=-1, # -1 = use all cores = faster
)
print scores
The scores are indeed a little bit worse than when we trained on the entire dataset (5574 training examples, accuracy 0.97). They are fairly stable though:
print scores.mean(), scores.std()
A natural question is, how can we improve this model? The scores are already high here, but how would we go about improving a model in general?
Naive Bayes is an example of a high bias - low variance classifier (aka simple and stable, not prone to overfitting). An example from the opposite side of the spectrum would be Nearest Neighbour (kNN) classifiers, or Decision Trees, with their low bias but high variance (easy to overfit). Bagging (Random Forests) as a way to lower variance, by training many (high-variance) models and averaging.
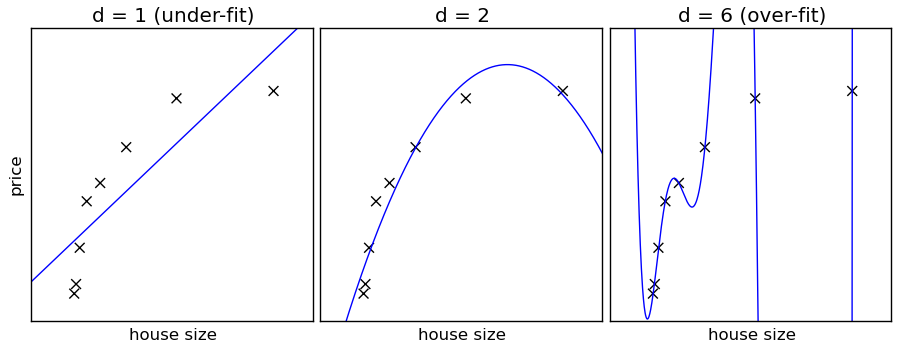
In other words:
- high bias = classifer is opinionated. Not as much room to change its mind with data, it has its own ideas. On the other hand, not as much room it can fool itself into overfitting either (picture on the left).
- low bias = classifier more obedient, but also more neurotic. Will do exactly what you ask it to do, which, as everybody knows, can be a real nuisance (picture on the right).
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
n_jobs=-1, train_sizes=np.linspace(.1, 1.0, 5)):
"""
Generate a simple plot of the test and traning learning curve.
Parameters
----------
estimator : object type that implements the "fit" and "predict" methods
An object of that type which is cloned for each validation.
title : string
Title for the chart.
X : array-like, shape (n_samples, n_features)
Training vector, where n_samples is the number of samples and
n_features is the number of features.
y : array-like, shape (n_samples) or (n_samples, n_features), optional
Target relative to X for classification or regression;
None for unsupervised learning.
ylim : tuple, shape (ymin, ymax), optional
Defines minimum and maximum yvalues plotted.
cv : integer, cross-validation generator, optional
If an integer is passed, it is the number of folds (defaults to 3).
Specific cross-validation objects can be passed, see
sklearn.cross_validation module for the list of possible objects
n_jobs : integer, optional
Number of jobs to run in parallel (default 1).
"""
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("Training examples")
plt.ylabel("Score")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r",
label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="Cross-validation score")
plt.legend(loc="best")
return plt
%time plot_learning_curve(pipeline, "accuracy vs. training set size", msg_train, label_train, cv=5)

(We're effectively training on 64% of all available data: we reserved 20% for the test set above, and the 5-fold cross validation reserves another 20% for validation sets => 0.8*0.8*5574=3567 training examples left.)
Since performance keeps growing, both for training and cross validation scores, we see our model is not complex/flexible enough to capture all nuance, given little data. In this particular case, it's not very pronounced, since the accuracies are high anyway.
At this point, we have two options:
- use more training data, to overcome low model complexity
- use a more complex (lower bias) model to start with, to get more out of the existing data
Over the last years, as massive training data collections become more available, and as machines get faster, approach 1. is becoming more and more popular (simpler algorithms, more data). Straightforward algorithms, such as Naive Bayes, also have the added benefit of being easier to interpret (compared to some more complex, black-box models, like neural networks).
Knowing how to evaluate models properly, we can now explore how different parameters affect the performace.
Step 6: How to tune parameters?¶
What we've seen so far is only a tip of the iceberg: there are many other parameters to tune. One example is what algorithm to use for training.
We've used Naive Bayes above, but scikit-learn supports many classifiers out of the box: Support Vector Machines, Nearest Neighbours, Decision Trees, Ensamble methods...
We can ask: What is the effect of IDF weighting on accuracy? Does the extra processing cost of lemmatization (vs. just plain words) really help?
Let's find out:
params = {
'tfidf__use_idf': (True, False),
'bow__analyzer': (split_into_lemmas, split_into_tokens),
}
grid = GridSearchCV(
pipeline, # pipeline from above
params, # parameters to tune via cross validation
refit=True, # fit using all available data at the end, on the best found param combination
n_jobs=-1, # number of cores to use for parallelization; -1 for "all cores"
scoring='accuracy', # what score are we optimizing?
cv=StratifiedKFold(label_train, n_folds=5), # what type of cross validation to use
)
%time nb_detector = grid.fit(msg_train, label_train)
print nb_detector.grid_scores_
(best parameter combinations are displayed first: in this case, use_idf=True and analyzer=split_into_lemmas take the prize).
A quick sanity check:
print nb_detector.predict_proba(["Hi mom, how are you?"])[0]
print nb_detector.predict_proba(["WINNER! Credit for free!"])[0]
The predict_proba returns the predicted probability for each class (ham, spam). In the first case, the message is predicted to be ham with > 99% probability, and spam with < 1%. So if forced to choose, the model will say "ham":
print nb_detector.predict(["Hi mom, how are you?"])[0]
print nb_detector.predict(["WINNER! Credit for free!"])[0]
And overall scores on the test set, the one we haven't used at all during training:
predictions = nb_detector.predict(msg_test)
print confusion_matrix(label_test, predictions)
print classification_report(label_test, predictions)
This is then the realistic predictive performance we can expect from our spam detection pipeline, when using lowercase with lemmatization, TF-IDF and Naive Bayes for classifier.
Let's try with another classifier: Support Vector Machines (SVM). SVMs are a great starting point when classifying text data, getting state of the art results very quickly and with pleasantly little tuning (although a bit more than Naive Bayes):
pipeline_svm = Pipeline([
('bow', CountVectorizer(analyzer=split_into_lemmas)),
('tfidf', TfidfTransformer()),
('classifier', SVC()), # <== change here
])
# pipeline parameters to automatically explore and tune
param_svm = [
{'classifier__C': [1, 10, 100, 1000], 'classifier__kernel': ['linear']},
{'classifier__C': [1, 10, 100, 1000], 'classifier__gamma': [0.001, 0.0001], 'classifier__kernel': ['rbf']},
]
grid_svm = GridSearchCV(
pipeline_svm, # pipeline from above
param_grid=param_svm, # parameters to tune via cross validation
refit=True, # fit using all data, on the best detected classifier
n_jobs=-1, # number of cores to use for parallelization; -1 for "all cores"
scoring='accuracy', # what score are we optimizing?
cv=StratifiedKFold(label_train, n_folds=5), # what type of cross validation to use
)
%time svm_detector = grid_svm.fit(msg_train, label_train) # find the best combination from param_svm
print svm_detector.grid_scores_
So apparently, linear kernel with C=1 is the best parameter combination.
Sanity check again:
print svm_detector.predict(["Hi mom, how are you?"])[0]
print svm_detector.predict(["WINNER! Credit for free!"])[0]
print confusion_matrix(label_test, svm_detector.predict(msg_test))
print classification_report(label_test, svm_detector.predict(msg_test))
This is then the realistic predictive performance we can expect from our spam detection pipeline, when using SVMs.
Step 7: Productionalizing a predictor¶
With basic analysis and tuning done, the real work (engineering) begins.
The final step for a production predictor would be training it on the entire dataset again, to make full use of all the data available. We'd use the best parameters found via cross validation above, of course. This is very similar to what we did in the beginning, but this time having insight into its behaviour and stability. Evaluation was done honestly, on distinct train/test subset splits.
The final predictor can be serialized to disk, so that the next time we want to use it, we can skip all training and use the trained model directly:
# store the spam detector to disk after training
with open('sms_spam_detector.pkl', 'wb') as fout:
cPickle.dump(svm_detector, fout)
# ...and load it back, whenever needed, possibly on a different machine
svm_detector_reloaded = cPickle.load(open('sms_spam_detector.pkl'))
The loaded result is an object that behaves identically to the original:
print 'before:', svm_detector.predict([message4])[0]
print 'after:', svm_detector_reloaded.predict([message4])[0]
Another important part of a production implementation is performance. After a rapid, iterative model tuning and parameter search as shown here, a well performing model can be translated into a different language and optimized. Would trading a few accuracy points give us a smaller, faster model? Is it worth optimizing memory usage, perhaps using mmap to share memory across processes?
Note that optimization is not always necessary; always start with actual profiling.
Other things to consider here, for a production pipeline, are robustness (service failover, redundancy, load balancing), monitoring (incl. auto-alerts on anomalies) and HR fungibility (avoiding "knowledge silos" of how things are done, arcane/lock-in technologies, black art of tuning results). These days, even the open source world can offer viable solutions in all of these areas. All the tool shown today are free for commercial use, under OSI-approved open source licenses.
Other practical concepts¶
data sparsity
online learning, data streams
mmap for memory sharing, system "cold-start" load times
scalability, distributed (cluster) processing
Unsupervised learning¶
Most data not structured. Gaining insight, no intrinsic evaluation possible (or else becomes supervised learning!).
How can we train anything without labels? What kind of sorcery is this?
Distributional hypothesis: "Words that occur in similar contexts tend to have similar meanings". Context = sentence, document, sliding window...
Check out this live demo of Google's word2vec for unsupervised learning. Simple model, large data (Google News, 100 billion words, no labels).
Where next?¶
A static (non-interactive version) of this notebook rendered into HTML at http://radimrehurek.com/data_science_python (you're probably watching it right now, but just in case).
Interactive notebook source lives on GitHub: https://github.com/piskvorky/data_science_python (see top for installation instructions).
My company, RaRe Technologies, lives at the exciting intersection of pragmatic, commercial system building and cutting edge research. Interested in interning / collaboration? Get in touch.